Peripateticism
Yuens' blog

高通神经网络处理引擎SNPE分析与评测
骁龙(SnapDragon)神经处理引擎(SNPE)是一个针对高通骁龙加速深层神经网络的运行时软件,高通在CSDN和其官网都提供了下载。
本文以SNPE 1.23为基准,将结合高通官方的SDK说明文档(高通在CSDN也提供了开发者社区,中文社区论坛,以及SNPE部分文档),介绍SNPE这一高通官方的神经网络处理引擎开发包。
开发中有疑问可在高通的CreatePoint检索相关文档或者在SNPE论坛提交疑问,或发邮件到support.cdmatech@qti.qualcomm.com。
因为SNPE的特殊性,本文重点考察:
- 不同runtime架构特点,调度关系,尤其是对DSP/AIP的HVX与HTA;
- 性能:CPU,FXP-CPU,GPU,GPU-FP16,FXP-DSP/FXP-AIP(FXP是int8量化);
- 模型的int8量化与DSP/AIP的加载时的量化策略。
本文将以如下目录展开:
- 高通与骁龙处理器
- SNPE特点与工作流
- SNPE组成架构
- SNPE性能与精度
- int8量化策略
1. 高通与骁龙处理器
这部分的内容改写自百度百科的词条:骁龙。高通骁龙是Qualcomm Technologies(美国高通公司)的产品。
1.1 历代产品
在2013年之前,骁龙处理器分为S1,S2,S3,S4四个层级,以区分不同的四代产品。
- 骁龙S1(2007-2011):MSM7225/7265采用ARM v6架构、单CPU核心,45nm制程,320MHz的Hexagon QDSP5,未集成GPU;2008年QSD8250/8650发布,Scorpion核心(ARM v7架构),Adreno 200 GPU,600MHz的Hexagon QDSP6。奠定S2/S3形态;
- 骁龙S2:由MSM8255/8655、MSM7230/7630和APQ8055构成。均采用了Scorpion CPU、Adreno 204 GPU、256MHz Hexagon QDSP5以及支持双通道333MHz LPDDR2内存,45nm制程,功耗降低。MSM8255处理器:HTC Incredible S、HTC Desire S、索尼爱立信LT15i、LT18i、OPPO R807、诺基亚Lumia 800等大多数的WP7系统手机;
- 骁龙S3:进入双核+1080P时代,产品线短,仅有MSM8260/8660和APQ8060三个版本(MSM8260如HTC Sensation、HTC Sensation XE、索尼LT26i、OPPO X905、小米手机),差异在于网络制式,相同点是均为双核Scorpion CPU、Adreno 220 GPU和400MHz Hexagon QDSP6。骁龙S3与骁龙S2、骁龙S1构成了2010年、2011年间QualcommSoC高中低搭配。
- 骁龙S4:
- Play系列:双核MSM8225/8625和四核MSM8225/8625Q,45nm,CPU为Cortex-A5核心与Adreno 203 GPU;
- Plus系列:双核Krait CPU、Adreno 205 GPU;
- 高端Pro,Prime系列:MSM8260A/8660A拥有双核Krait CPU、双核/四核Adreno 320。APQ8064拥有高性能四核心Krait CPU。
这一部分虽然只是罗列,但是能看出S1~S4的每一代都几乎都是基于ARM架构+自家DSP+GPU的异构平台。
1.2 骁龙处理器
后来的骁龙处理器,主要包括:800系列、700系列、600系列、400系列和200系列处理器。
800系列特点:
- 该系列定位高端。截至目前,855是高通最新的旗舰级手机处理器;
- 9款:855/845/835/821/820/810/808/805/801/800;
- Krait架构、ARM公版架构、定制的Kyro架构:
- 800、801、805都基于Krait架构:该架构基于ARMv7-A指令集、自主设计采用28纳米工艺的全新处理器微架构;
- 810使用64位ARM公版架构;
- 骁龙820采用定制架构Kryo:高通推出的首款定制设计的64位CPU架构。821比820性能提升高达10%,此外Hexagon™ 680 DSP 带来性能、电池续航的优化。
其它系列:
- 700系列:高端级,支持人工智能引擎(我猜应该是指SNPE)、功耗优化;
- 600系列:高端级,手机、平板电脑、嵌入式等。15款:670/636/632/660/653/630/626/652/650/617/616/615/610/602A/600;
- 400系列:大众级,10款:450/439/429/427/435/430/425/415/412/400;
- 200系列:入门级,4款:212/210/208/200。
1.3 支持SNPE的处理器
支持SNPE的骁龙处理器列表如下:
- 9款800系列中的5款(855/845/835/821/820);
- 1款700系列(710);
- 15款600系列中的6款(660/652/636/630/625/605);
- 1款400系列(450)。
参照前面骁龙处理器系列,可以看出SNPE主要针对中高端机型中的800、600系列。
| Snapdragon Device | CPU | GPU | DSP | AIP |
|---|---|---|---|---|
| Qualcomm Snapdragon 855 | Yes | Yes | Yes (CDSP) | Yes (CDSP) |
| Qualcomm Snapdragon 845 | Yes | Yes | Yes (CDSP) | No |
| Qualcomm Snapdragon 835 | Yes | Yes | Yes (ADSP) | No |
| Qualcomm Snapdragon 821 | Yes | Yes | Yes (ADSP) | No |
| Qualcomm Snapdragon 820 | Yes | Yes | Yes (ADSP) | No |
| Qualcomm Snapdragon 710 | Yes | Yes | Yes (CDSP) | No |
| Qualcomm Snapdragon 660 | Yes | Yes | Yes (CDSP) | No |
| Qualcomm Snapdragon 652 | Yes | Yes | No | No |
| Qualcomm Snapdragon 636 | Yes | Yes | No | No |
| Qualcomm Snapdragon 630 | Yes | Yes | No | No |
| Qualcomm Snapdragon 625 | Yes | Yes | No | No |
| Qualcomm Snapdragon 605 | Yes | Yes | Yes (CDSP) | No |
| Qualcomm Snapdragon 450 | Yes | Yes | No | No |
除了关注CPU和GPU外,比较引人注目的是DSP和AIP。其实AIP也是一种DSP,但根据表格中的值发现有CDSP和ADSP之分。只在官方文档中的支持设备表格与例子部分看到有CDSP,其它地方并没检索到更多信息,不过文档中说CDSP还是ADSP取决于设备:
This module runs on the ADSP or the CDSP, depending on the target. Please refer to the Snapdragon Device Support Matrix table in the Overview section to determine SNPE support of DSP on various Snapdragon devices. SNPE automatically detects the appropriate DSP.
但也在网上查到高通有2种DSP:
- mDSP is the Modem DSP, which allows the modem to outsource processing;
- aDSP is the Application DSP, which allows the device to process simple sets of data on low power, without having to wake up the Application processor (AP).
下图是骁龙800处理器,来自Hexagon hotchips2013的PPT,可以看到有aDSP与mDSP。
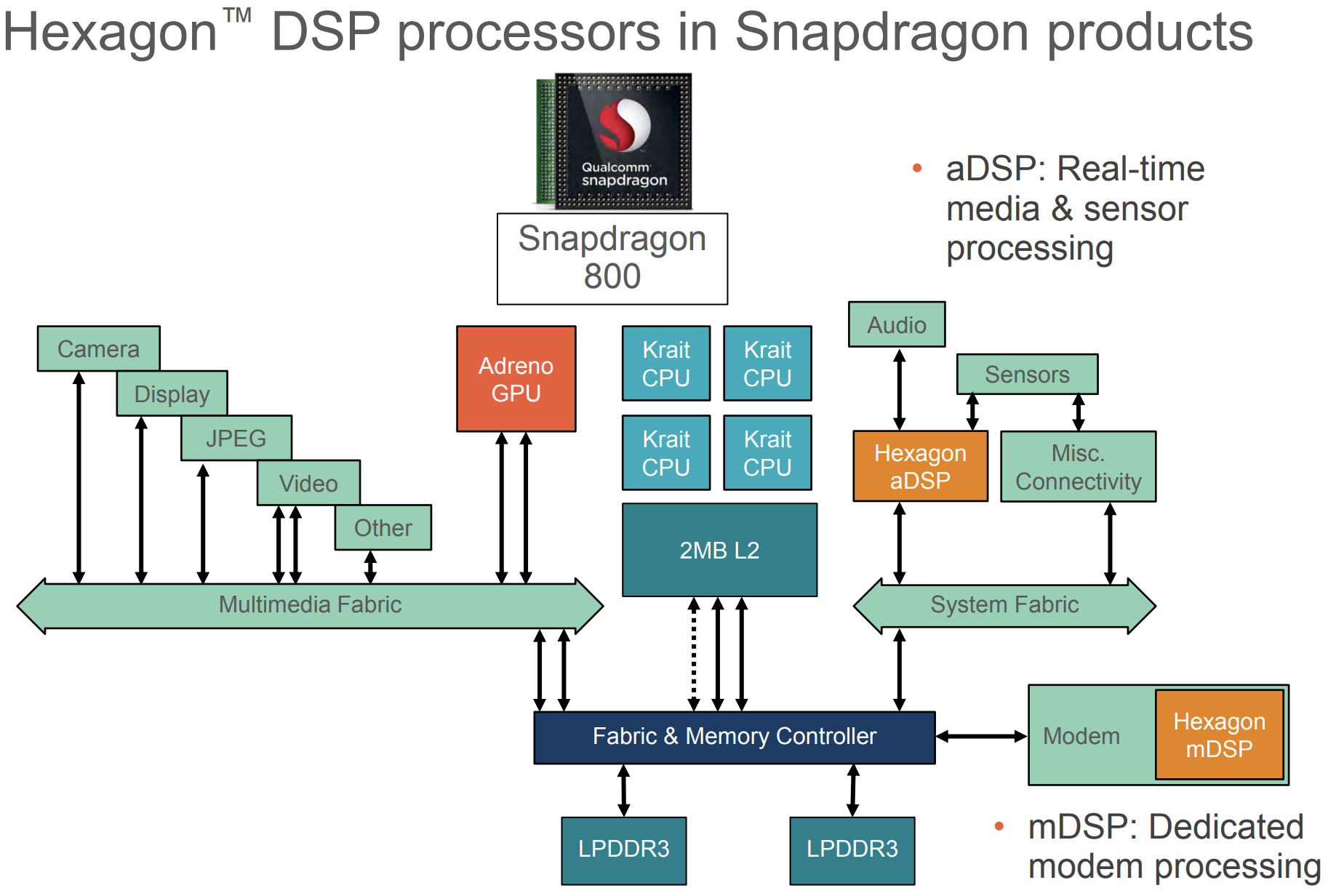
1.4 Hexagon DSP
列表中CPU、GPU都比较熟悉,但是对后两个DSP和AIP不了解。根据和高通平台的手机产品中的Hexagon百度百科对词条Hexagon(高通骁龙处理器的DSP名称,DSP是数字信号处理器)的解释:
Hexagon Digital Signal Processor (DSP),高通的Hexagon计算DSP,作为高通研发的世界一流处理器,集成了CPU和DSP功能,能支持移动平台多媒体和modem功能的深度嵌入处理。拥有高级的可变指令长度、超长指令字、支持硬件多线程机制的处理器架构,Hexagon架构和核心家族给高通带来了modem和多媒体应用的性能和功耗优势,是高通骁龙处理器的关键组件。
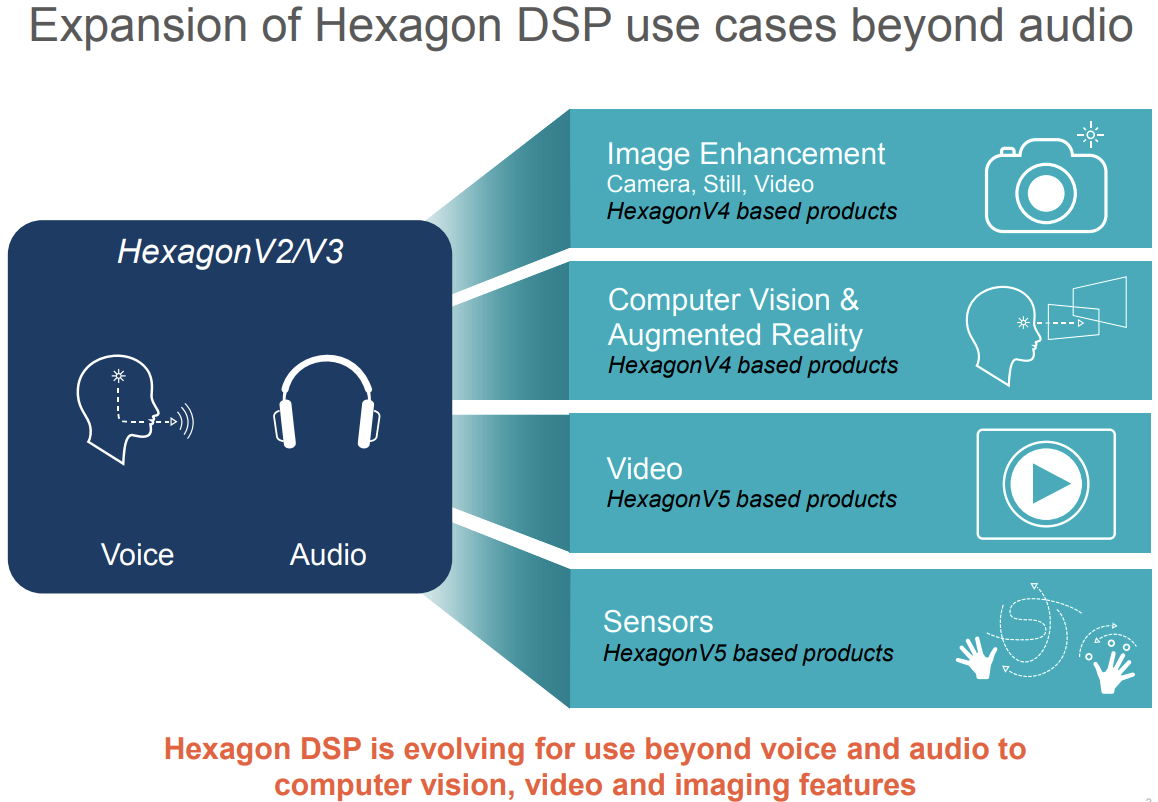
自骁龙品牌建立之初就有了DSP,早期DSP仅用于语音和简单的音频视频解码播放,随着智能手机使用需求加大,包括摄像头和传感器功能的信号处理任务都可由DSP完成,DSP比CPU更擅长在低功耗下处理这些任务。
其基本特点有:
- DSP相比CPU可实现高性能计算和高能效(省电);
- 用于卸载CPU任务,利用异构计算支持实时在线任务;
- 音频任务。在无延迟、无失真的情况下流式传输音频,消除背景噪声;
- 视觉任务。文本识别、对象识别、图像增强和图像内的面部识别。
下图是几种典型的Hexagon DSP比较:
| Hexagon Core Architecture | ||||
|---|---|---|---|---|
| Hexagon 400 | Hexagon 500 | Hexagon 600 | ||
| Key Attributes | Fixed Point | Floating Point | Hexagon Vector eXtensions (HVX) | |
| Snapdragon Chipsets(SDxxx) | Premium Tier | 801, 805, 808, 810 | 820, 821 | |
| High Tier | 602A | 615, 161, 617, 625, 650, 652 | ||
| Mid Tier | 410, 412, 415, 430 | |||
| Low Tier | 208, 210, 212 | |||
| SDK Version | AddOn_600 | SDK 2.0 | SDK 3.0 | |
| Command Line Tools | 5.0, 5.1 | 5.0, 5.1, 6.2, 6.4 | 7.2, 7.3 | |
| RTOS | QuRT | QuRT | QuRT |
上表分别是Hexagon400,5000和600系列,其中关键特性可以看到Hexagon 400、500、600系列分别支持定点、浮点、Hexagon Vector eXtension(HVX)。根据不同的系列也有不同的Snapdragon的芯片型号,分别对应旗舰、高端、中端和低端,其中Snapdragon 800系列都属于旗舰级别的芯片,占据了Hexagon 500和600系列的DSP。不同DSP系列也有对应的不同的SDK版本和命令行工具,支持的实时操作系统是QuRT(更多的信息我就没找到了)。
1.4.1 发展历史
几乎每一年高通都在为性能和低能耗而改动架构和实现:

- 2004 开始研发一种新的高性能DSP处理器架构
- 2011 发起Hexagon试用计划,让客户在DSP上编程,从而探索为了性能、功耗和其他需求释放ARM核心所带来的性能和功耗提升
- 2012 多个Hexagon核心处理器伴随着每次高通发布4G LTE modem推出,现在已经发展到第5代,并且集成进了所有的modem和应用芯片当中
- 2013 发布了第一个公开可用的Hexagon DSP研发环境-Hexagon SDK
1.4.2 架构设计核心与特性
Qualcomm_HexagonDSP开发入门与提高概述描述了其架构设计核心与特性,下图是Hexagon 680 DSP版本的特性图:

其特性包括如下几个特点(可能有重复):

- 硬件多线程(对应上图左下角):由时间多线程(TemporalMultiThreading,TMT)实现,该模式下频率600MHz的物理核心可被抽象成三个频率200MHz的核心。通过高优先级调度算法来调度尽可能多的执行单元,可以认为硬件线程是使用共享内存的独立处理器核心,并用传统软件线程来编程。由RTOS负责把软件线程映射到几个处理器硬件线程上,它在全局调度最高优先级的软件线程并且总是把中断导入到最低优先级的硬件线程;
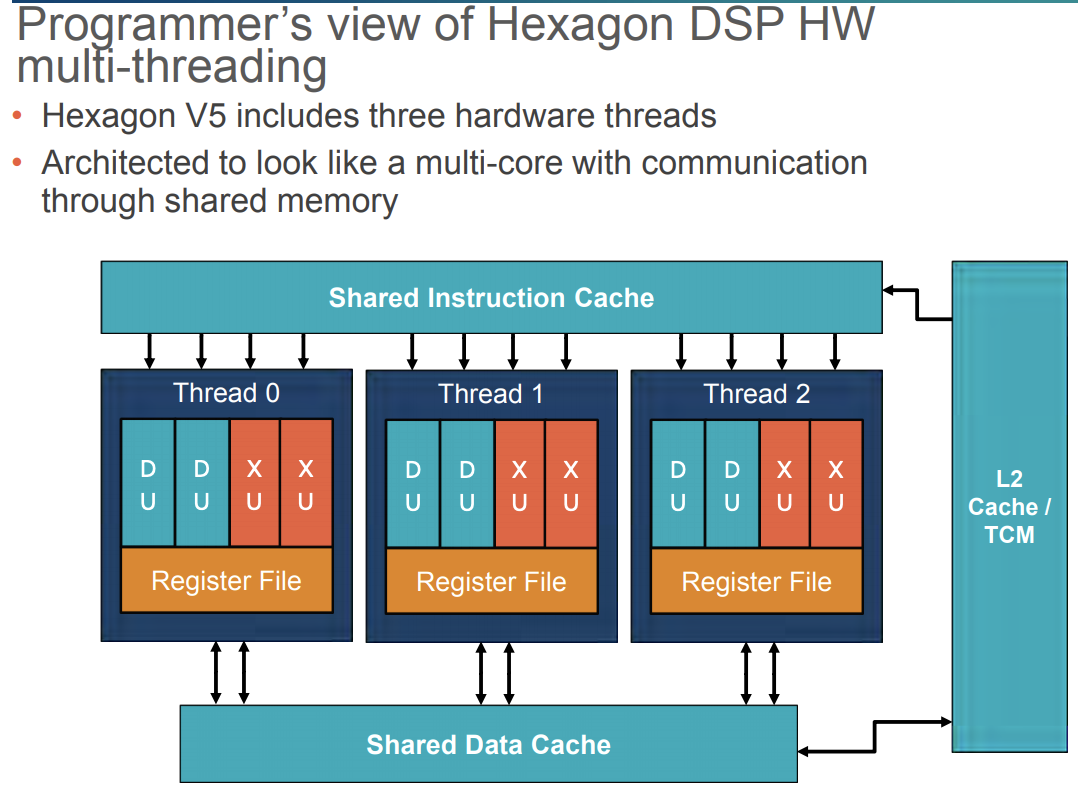
- 特权级:一种机制来保护数据和阻止恶意行为,确保计算机安全(我想这可能是代码签名,目前在安卓上使用Hexagon限制很多,不仅有高通SOC也有要HVX支持、禁止Secure boot、对手机ROOT、将dsp的库上传到对应的系统路径外,还需要下载Hexagon SDK去对代码签名,才能跑Hexagon NN。具体见Frequently asked questions — MACE documentation);
- 指令集优化
- 允许相关/不相关指令分组:例如,通常的加载-比较-分支语句能在单个Hexagon指令包中表达,这样的技术使来自不规则控制代码应用中的指令高度并行执行成为可能。
- 支持超长指令字(VLIW,Very Long Instruction Word)风格的指令分组:VLIW是一种非常长的指令组合,它把许多条指令连在一起,增加了运算的速度;
- 集成丰富的专门适应于信号处理的指令:包括16位和32位小数和复杂的数据类型、32位浮点型、完整的64位整数运算;
- 支持计算向量扩展(HVX):主要用于视频、计算机视觉,减轻CPU负担(SNPE里有个小节Adding HTA sections有讲怎么在部署的时候发挥HVX的能力);
- 引入低功率岛(low power island):
- 一个独立、用于传感器持续工作时关闭其他芯片来省电、基于Hexagon架构的DSP;
- 原生支持Android L接入,包括计步器或活动计数器,以及传感器辅助定位等组件都能以更低的功耗持续运行;
- 低功率岛和传统DSP一样具备可编程能力。
因而,我们也可以看出Hexagon架构设计核心:如何在低功耗的情况下能够高性能地处理各种各样的应用。
1.4.3 架构特点
此外,需要特别说明的是因DSP具有不同于CPU和GPU架构,因而有两个关键特点:
- DSP最大化了每个时钟周期所能完成的工作:DSP旨在执行复杂的并行计算,而并行计算在许多信号处理应用中是很常见的。例如,Hexagon DSP能够执行主要的快速傅氏变换(FFT)循环,即在一个时钟周期进行29个“精简指令集计算(RISC)操作”。通过搭载针对FFT进行优化的硬件和指令集架构(ISA),FFT可在更短的时间内以更高的性能——以及更低的功耗运行。
- DSP在较低时钟频率下提供高性能,以节省功耗。功耗与时钟频率和电压的平方成正比,以更高频率运行时钟需更高电压,这导致功耗的迅速增长。例如,Hexagon DSP能够通过硬件多线程技术和最大化每个时钟周期所能完成的工作,在低时钟频率下又能提供高性能。
以上是对高通Hexagon DSP的一个基本认识,基本概念的知识铺垫完了,下面继续讲解SNPE的相关内容。
2. SNPE特点与工作流
2.1 SNPE特点
以下SNPE的特点改写自官方文档:
- 支持自定义网络
- 支持Snapdragon CPU、Adreno GPU、Hexagon DSP上做推理计算
- 支持x86 Linux系统下对网络执行Debug
- 支持将Caffe, Caffe2, ONNX和TensorFlow模型转换为SNPE的DLC模型
- 支持Hexagon DSP对DLP模型做8位定点的推理计算
- 支持网络Debug和性能分析的工具
- 支持通过C++或Java对模型集成为应用
2.2 SNPE工作流
使用SNPE部署模型的一般工作流程分为如下图中所描述的两个阶段:第一阶段由Caffe/Caffe2/TensorFlow完成模型训练;第二阶段将模型部署到高通设备上: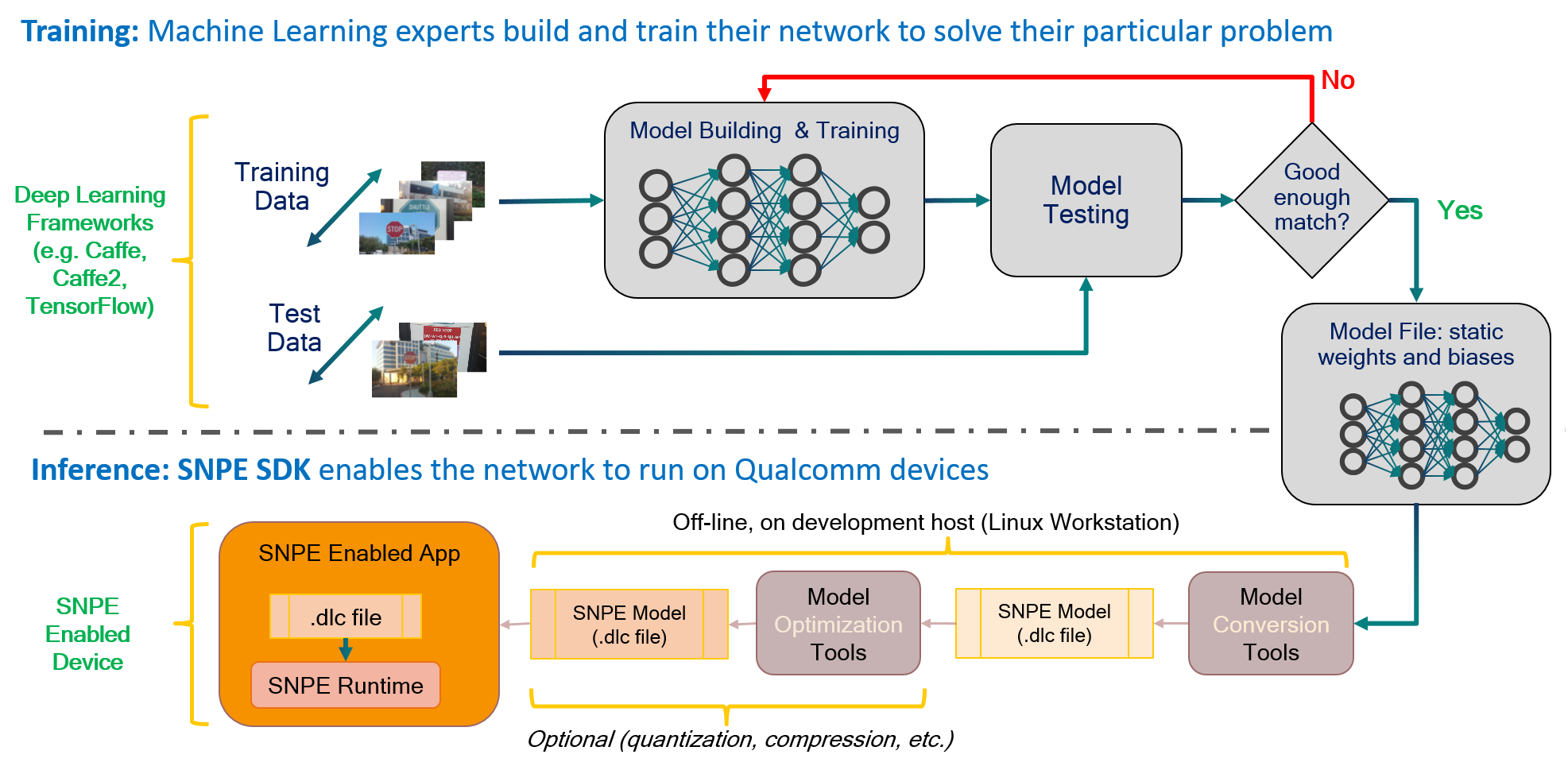
部署阶段前,先将模型用SNPE提供的工具,将模型转换为SNPE特有的DLC(Deep Learning Container)文件格式,转换好后就可在骁龙的CPU/GPU/DSP核心上执行推理了。具体而言包含以下步骤(或见上图):
- 将模型转换为SNPE支持的DLC格式;
- 量化是可选的,若部署到Hexagon DSP Runtime或者CPU-FXP即CPU定点,需要离线地对模型做8位定点量化(DSP也可以免去这一离线量化的步骤),离线量化需指定数据;
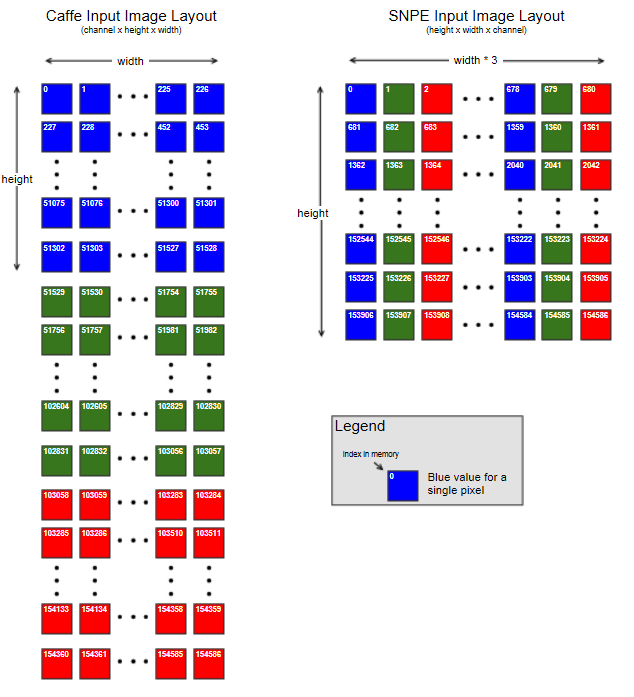
- 为模型准备用于测试的输入数据:用./models/alexnet/scripts/下的脚本,转换jpg图像文件为raw格式,生成raw_list.txt文件(注:SNPE的输入数据格式是BGR,且每个像素点值BGR是连续的,即NHWC格式,如下图);
- 根据文档,调用接口执行模型。文档里提供了4种方式:
- 可执行文件命令行调用,实际是C++例子编译好的可执行文件;
- C++接口,调用SNPE的C++ API;
- Java接口;
- Python接口,实际还是调用C++编译出来的可执行文件。
上面那个图略显复杂,下面这张图的流程描述根据这4个步骤,更清楚一些:
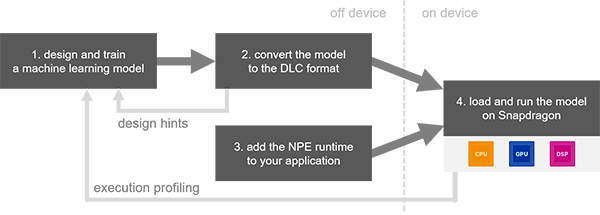
以上便是SNPE的特点和工作流。
3. SNPE组成架构
接下来介绍SNPE的运行时即Runtime,分两步骤介绍:Snapdragon NPE Runtime与AIP。前者是总览全局即4个Runtime,后者针对AIP这一特别的DSP着重介绍。
3.1 Snapdragon NPE Runtime
先说全局的Snapdragon NPE Runtime,其包含CPU、GPU和DSP(AIP也是DSP,他们的使用教程可参考官方文档Tutorials Setup章节),所以整体架构如下图,这也是对整个SNPE推理框架的概括性架构描述:
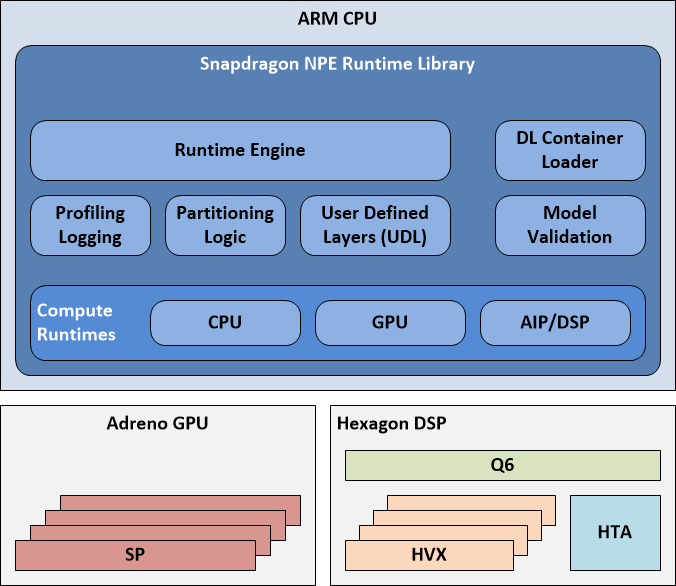
上图包括三个独立的硬件部分,分别是ARM CPU、Adreno GPU和Hexagon DSP:
-
灰色框的ARM CPU,其内的蓝色框就是Snapdragon NPE Runtime Library。该图从一个高层级来描述SNPE Runtime整个软件架构,其中除去最底层的Compute Runtimes外,还包含:
- DL Container Loader : 读取由snpe-framework-to-dlc转换工具转换得到的SNPE模型格式的DLC文件;
- Model Validation : 验证DLC文件与runtime是否匹配(或者说,该支持runtime是否支持该模型),因为在SNPE中,不同Runtime实现了不同的层,并不是说可以拿GPU或者DSP跑通整个网络,可能部分层不支持,需要切换到CPU上,具体不同Runtime支持的层可参考文档Supported Network Layers小节;
- Runtime Engine : 在需要的rumtime(s)上执行模型,也包括汇总性能分析数据与用户自定义层;
- Partitioning Logic : 处理模型,也包括用户自定义层、验证信息、 也可对模型分割;
- 对于用户自定义层(UDL),会在执行UDL前后打断执行过程;
- fallback mode(备选模式):该模式默认开启,若subnets也就是部分名在不同的runtime上执行如DSP,但是遇到了DSP目前还没实现的层,这时候就会交给CPU来执行,结束后继续交还给Target runtime执行。
- Compute Runtimes:
- CPU Runtime:支持float和int8;
- GPU Runtime:支持float和float16的混合精度;
- DSP Runtime:基于Q6调度Hexagon DSP来执行模型,Q6会去调用Hexagon NN在HVX(Hexagon Vector eXtensions)上执行计算任务(这里DSP runtime和AIP runtime很像,关于Q6、HVX、HTA关系见后文AIP runtime小节);
- AIP Runtime:用Hexagon DSP借助Q6,Hexagon NN和HTA执行模型。 注:另外,在前文设备列表的DSP和AIP部分,可以看到DSP和AIP要么是cDSP或者aDSP。
-
Adreno GPU
- 图上有4个SP,这里参考NVIDIA GPU的概念,SP即streaming processor,是最基本的处理单元。GPU并行计算通多个sp同时做处理。现在SP的术语已经有点弱化了,而是直接使用thread来代替,一个SP对应一个thread。 通常一个SM(streaming multiprocessor,硬件角度:GPU由多个SM等其它部分组成,一个SM含有多个SP,当然还有寄存器资源、shared memory、L1Cache、Schedule,SPU、LD/T单元等)中的SP(thread)会分成几个warp(warp是SM调度和执行的基础概念),一般一个warp中有32个执行相同指令一起工作的thread(SP),若只有1个thread工作,其它31个thread会接收warp生成的掩码,从而不工作进入静默状态。
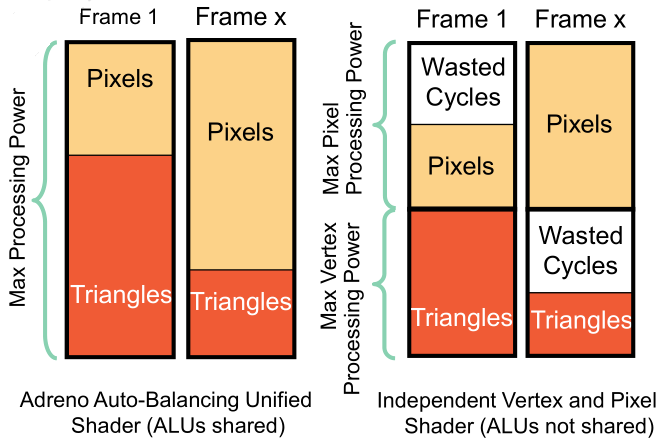
- 统一渲染架构(Unified shader architecture)是Adreno GPU的一大特点:计算单元(ALU)即支持顶点shader又支持像素/片段shader,顶点着色器和片段着色器不存在物理分割,可充分利用系统的资源避免浪费。
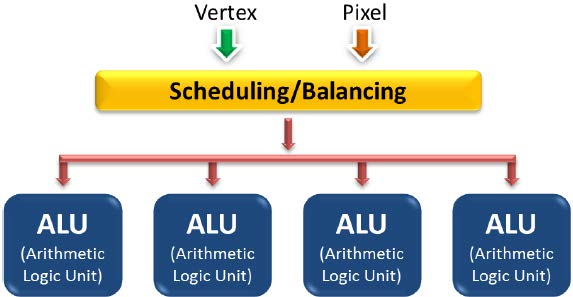
例如下图,第一帧顶点计算多就分配给顶点着色器多一些ALU,而第X帧像素运算多就分配给像素着色器多一些ALU。而不支持统一渲染架构的GPU是平均分配ALU的,比如第一帧像素处理少用不完自己的ALU,但是却无法共享给顶点着色器,造成巨大浪费。
例如下图,第一帧顶点计算多就分配给顶点着色器多一些ALU,而第X帧像素运算多就分配给像素着色器多一些ALU。而不支持统一渲染架构的GPU是平均分配ALU的,比如第一帧像素处理少用不完自己的ALU,但是却无法共享给顶点着色器,造成巨大浪费。
这里只做简单介绍,更多Adreno GPU特性可以参考:Adreno GPU详细介绍。
这里只做简单介绍,更多Adreno GPU特性可以参考:Adreno GPU详细介绍。
-
Hexagon DSP:DSP主要的应用就是AI,一篇针对高通855芯片(小米9采用)的深度解析文章:2019年安卓旗舰第一芯片 高通骁龙855强在哪?表示,Snapdragon 855内集成Hexagon 690。

- Q6:根据前文和官方文档的描述,应该是一个调度器用于编排管理向量加速器和张量加速器,但是也查到高通DSP有QDSP5,QDSP6架构,猜想这个Q6是QDSP6的缩写,问了SNPE论坛,并没有得到官方人员的答复,文档里也没有更多关于Q6的介绍;
- HTA(Hexagon Tensor Accelerator):张量处理单元,最多支持16位的数据(我猜想应该就是SNPE里的AIP Runtime,但目前在SNPE的文档中看只支持int8类型,或许是Snapdragon 855前的DSP只支持int8),为复杂向量矩阵结构和多维向量数组服务,如卷积,高通官方声称集成HTA的原因就是为了更强大的图像处理能力。Hexagon 690首次引入1个张量加速器(HTA),为特定的复杂机器学习任务提供更高的吞吐量。所以高通吹嘘称,骁龙 855 与前代移动平台相比可实现高达 3 倍的 AI 性能提升,而与华为麒麟 980 相比,性能提升最高可达 2 倍;
- HVX(Hexagon Vector eXtensions ):Hexagon 690包含4个1024b的HVX向量处理单元(上一代Hexagon 680/685包含4个标量处理单元和2个1024b的向量处理单元),主要应用在机器学习任务,大多是针对INT8优化(我猜只支持INT8,从SNPE跑DSP runtine的情况来看,只支持int8模型)。
本部分针对DSP介绍的较少,后面会更关注DSP开发和底层调度原理等相关背景知识。
3.2 AIP Runtime
AIP (AI Processor) Runtime是Q6、HVX和HTA三者在执行模型时候的一层软件抽象。
3.2.1 部署前提条件
让模型在AIP上执行的前提条件:
- 看硬件设备是否支持(查看前文中支持SNPE处理器的硬件列表);
- 量化模型如caffe转DLC格式时(见下图),需模型量化命令中带–enable_hta参数(–enable_partitions参数可选,表示一部分即subnet在HTA上执行,一部分即subnet在HNN上执行,调度通过Q6。具体见下文)。 相比量化,这个过程会调用HTA编译器,将编译好的AIP执行部分以二进制形式嵌入到DLC中(操作见文档中Adding HTA sections小节);

- 在设备上使用DSP和AIP(也是DSP)的runtime是动态加载的,从而实现SNPE与AIP runtime的通讯。如安卓需要将对应DSP的库文件上传到对应路径,并export导入相关动态库和设备位置的环境变量ADSP_LIBRARY_PATH,ADSP或CDSP(即无论DSP或AIP runtime)都需要该环境变量。
3.2.2 内部调度
SNPE在用AIP计算时,会通过加载DSP的动态库从而与AIP runtime通讯,但调度管理器我想应该是Q6,通过Q6去管理使用HTA和HNN,下图的结构描述可以看到Q6是Hexagon DSP上的一部分,Q6这部分应该都是软件层面。
模型调用AIP执行过程中,SNPE Runtime上的AIP runtime会调用DSP执行器(executor,位于DSP动态库中),DSP执行器来调用HTA和HVX来管理模型的执行:
- 当DSP executor遇到HTA模型(部分),会通过HTA Driver调用HTA来执行模型该部分subnet;
- 当DSP executor遇到HVX模型(部分),会通过Hexagon NN来调用HVX执行该部分subnet。
不同部分在DLC量化过程中将相应的描述信息写到了量化后的DLC文件中,DSP executor遇到对应描述信息从而选择对应硬件驱动调用执行,见下图。
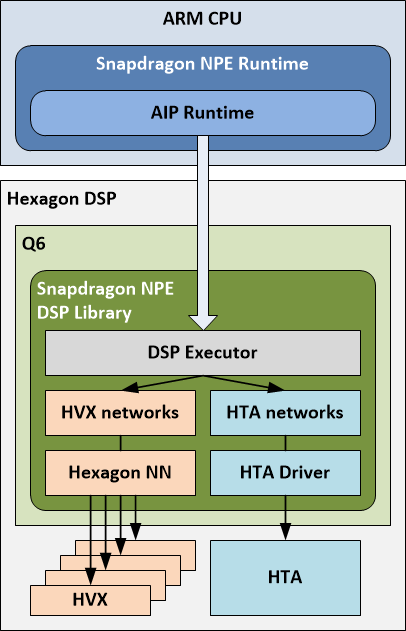
上图中,我的理解是分为ARM CPU和Hexagon DSP两部分,两部分又有各自软硬件层面,箭头是指调用关系。两部分中,最底层都是硬件上层是Runtime或者调度器,没查到Q6的信息,我想可能是固化到硬件层面的调度器类似driver,但根据SNPE文档描述Q6类似调度器(orchestrated by Q6),让Hexagon NN与HVX硬件、HTA Driver与HTA硬件打通。
3.2.3 模型执行
因量化时可以选是否启用–hta_partitions以及对应的层数,若启用得到的模型会包含subnet。在执行过程中遇到subnet会被AIP runtime打断,根据subnet描述信息调用不同的硬件设备执行。
- HTA subnets:模型部分由HTA Compiler编译,位于DLC文件得到HTA部分;
- HNN subnets : 模型剩余部分可在DSP上调用Hexagon NN库完成计算。
目前,AIP只支持单独的HTA subnet + 单独的HNN subnet。此外,Adding HTA sections小节中还提到其它限制:HTA和HNN subnets只支持层的单一输入与输出;HTA subnet需要从第一层开始。
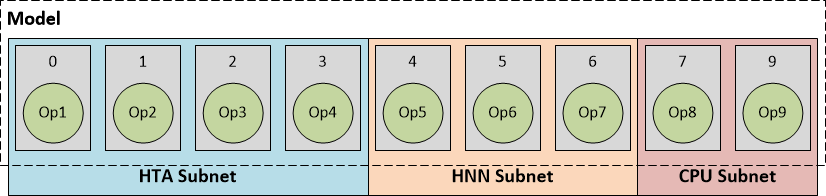
为了清楚地描述模型执行流程,描述DLC中的模型组成如下图所示,圆圈表示模型中的计算操作,方块表示一层。
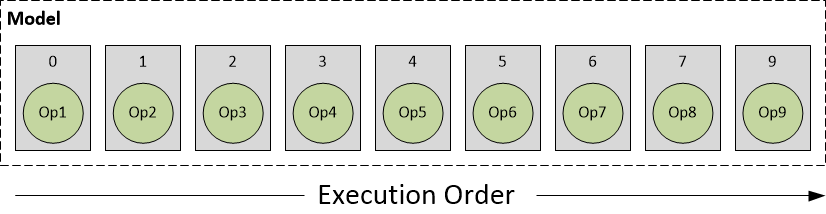
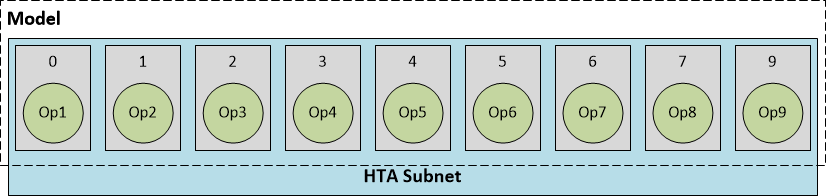
因而根据HTA、HNN subnets的分片,可将模型执行分为如下几种情况:
- HTA subnet:runtime识别出DLC中描述信息整个网络都是HTA网络,完成计算后,如有必要先做计算结果的转换和反量化,再将输出结果返回给ARM CPU;
- HTA subnet + HNN subnet:根据量化时的参数选择,模型的0-3层在HTA上计算,后面在HNN上计算。HTA subnet的输出交给HNN subnet作为输入,最后将结果给ARM CPU(同样,如有必要则需要反量化或转换操作);
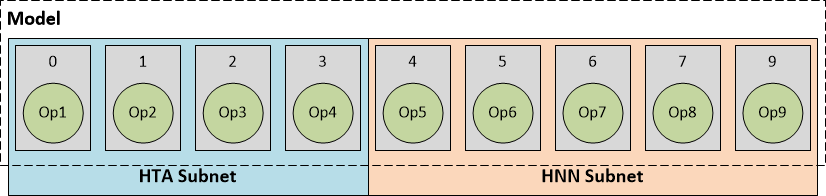
- HTA subnet + HNN subnet + CPU subnet:这部分不同在于,前两个子网络在AIP上计算,最后几层交给ARM CPU完成计算。
4. SNPE性能与精度
下面是SNPE在小米MIX2上3个Runtime上做的benchmark。
- MIX2的SOC是骁龙835
- CPU:8核的大小核架构,1.9GHz+2.45GHz,大小核均为 Kryo280架构;
- 大核心频率2.45GHz,其大核心簇带有2MB的L2 Cache;
- 小核心频率1.9GHz,其小核心簇带有1MB的L2 Cache;
- GPU为Adreno 540@670MHz;
- DSP:Hexagon 690 DSP;
- AIP:无。
benchmark的4个模型有:AlexNet,GoogleNet,MobileNetV1/V2,SqueezeNetV1.1。一切参数根据原文作者的CaffeModel和Prototxt基于SNPE提供的转换或量化工具而来。
4.1 AlexNet
| ms | cpu | fxp-cpu | gpu | gpu-fp16 | fxp-dsp |
|---|---|---|---|---|---|
| total inference time | 196-278 | 202-327 | 25 | 23 | 23 |
| forward propagate time | 191-272 | 187-313 | 24 | 23 | 22 |
| 正确性验证 | ✔️ | ❌ | ✔️ | ✔️ | ✔️ |
- 正确性验证,根据./models/alexnet/scripts/show_alexnet_classifications.py下的脚本,通过图像真实类别与网络分类类别比对,并非逐个featuremap单个元素值比较;
- fxp前缀:是使用snpe-dlc-quantize量化过的模型, 其量化策略采用8 bit的Tensorflow方式编码(下面相同),使用snpe的默认量化方式(snpe提供两种量化方式,见后文int8量化策略章节)。
4.2 GoogleNet
| ms | cpu | fxp-cpu | gpu | gpu-fp16 | fxp-dsp |
|---|---|---|---|---|---|
| total inference time | 418 | 222 | 31 | 29 | 22 |
| forward propagate time | 412 | 212 | 31 | 28 | 22 |
| 正确性验证 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
4.3 MobileNetV1
| ms | cpu | fxp-cpu | gpu | gpu-fp16 | fxp-dsp |
|---|---|---|---|---|---|
| total inference time | 909 | segfault | 12 | 13 | 15 |
| forward propagate time | 902 | segfault | 12 | 13 | 14 |
| 正确性验证 | ❌ | segfault | ❌ | ❌ | ❌ |
4.4 MobileNetV2
| ms | cpu | fxp-cpu | gpu | gpu-fp16 | fxp-dsp |
|---|---|---|---|---|---|
| total inference time | 1194 | 509 | 11 | 12 | 12 |
| forward propagate time | 1187 | 495 | 11 | 12 | 11 |
| 正确性验证 | ❌ | ❌ | ❌ | ❌ | ❌ |
4.5 SqueezeNetV1.1
| ms | cpu | fxp-cpu | gpu | gpu-fp16 | fxp-dsp |
|---|---|---|---|---|---|
| total inference time | 116 | 96 | 9 | 8 | 12 |
| forward propagate time | 110 | 88 | 9 | 8 | 11 |
| 正确性验证 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
可以看出:
- 大模型DSP更有优势,小模型GPU和DSP差不多。但不能忽略的是DSP跑的都是int8量化的模型,若非量化模型,可能执行前DSP会自动量化模型初始化会占用一部分可被忽略的时间。
- 整体而言,GPU和DSP性能差不多,但GPU是float32或者float16,精度比只能跑int8的DSP要高一些,对检测、分割(如超分辨率)任务应该GPU(能加载原始非量化的模型)表现更好。GPU跑相同模型,float32和float16的推理时间差别不大,而且本身float16也能满足计算需要,在GPU情况下,可能选float32的模型更好;
- 高通对CPU的优化力度有限,毕竟DSP和GPU就是用来卸载CPU负载的,CPU与GPU/DSP相比,推理时间上慢了1到2个数量级;
- int8量化精度低。mobilenetv1和v2对于量化模型,无论是离线通过脚本转换,或者DSP直接加载float32模型做的int8定点量化,分类模型的计算结果全都错误。
5. int8量化策略
上面的benchmark数据中,mobilenet计算结果都是错的。在高通的SNPE论坛上发了关于MobileNet的int8分类精度问题,官方人员称目前的确有问题,反而设计出一种对量化友好的MobileNet的Seperable Convolution的方式:A Quantization-Friendly Separable Convolution for MobileNets,后面会讨论。
不过在此之前,我们先来看一下当前SNPE的量化方式,文档称SNPE采用的int8量化方式与TensorFlow一致(也正因如此,被坑了,mobilenet系列的分类网络,在int8量化计算结果上都不正确):
- Quantized DLC files use 8 bit fixed point representations of network parameters. The fixed point representation is the same used in Tensorflow quantized models.
此外,还提供了针对不同Runtime的量化情况表格:
| Runtime | Quantized DLC | Non-Quantized DLC |
|---|---|---|
| CPU or GPU | Compatible. The model is dequantized by the runtime, increasing network initialization time. Accuracy may be impacted. | Compatible. The model is native format for these runtimes. Model can be passed directly to the runtime. May be more accurate than a quantized model. |
| DSP | Compatible. The model is native format for DSP runtime. Model can be passed directly to the runtime. Accuracy may be different than a non-quantized model | Compatible. The model is quantized by the runtime, increasing network initialization time. Accuracy may be different than a quantized model. |
| FXP_CPU | Compatible. The model is in supported format for FXP_CPU runtime. Model can be passed directly to the runtime. | Incompatible. Non-quantized models are not supported by the FXP_CPU runtime. |
| AIP | Compatible. The model is in supported format for AIP runtime. Model can be passed directly to the runtime. | Incompatible. Non-quantized models are not supported by the AIP runtime. |
需注意的是,FXP_CPU和AIP不支持非量化模型。FXP_CPU会出现runtime error,AIP不清楚没有试过。
5.1 量化算法
SNPE支持量化的模型,正如前面所述。
- FXP-CPU runtime跑的就是int8量化的模型,但前提要对DLC格式的模型使用量化脚本来量化;
- DSP和AIP runtime也可以跑量化模型,虽然模型int8量化不是必须的,但是之后DSP加载模型初始化时,也会对加载的参数量化,但可能DSP自动加载量化会有精度不如用脚本对模型量化的方式。
虽然SNPE对其量化代码没开源,但是文档表示其float转int8定点表示与TensorFlow中的量化方式一样,下面让我们一探究竟。
基本信息:
- 量化包含了输入值的整个范围,量化后的范围介于0到255,左开右开;
- 量化区间的最小值是0.01;
- 浮点0可以被精确表示(非对称量化,0可以选择是否保留表示,具体见后文)。
算法流程:
- 计算输入数据的浮点范围:得到最大和最小浮点值;
- 计算encoding-min和encoding-max:这俩参数用于第三步的量化;
- encoding-min:将以定点的形式表示,表示input的浮点值的最小值;
- encoding-max:将以定点的形式表示,表示input的浮点值的最大值;
- 每一步的浮点值:step_size := (encoding_max - encoding_min) / 255,不过这里先临时用第一步得到的float_max与float_min来表示encoding_max与encoding_min。encoding_max与encoding_min的范围区间不能小于0.01。那么有:encoding_max := max(float_max, float_min+0.01),encoding_min后面再调整;
- 0的浮点值必须精确表示,根据输入值分情况:
- 全为正:encoding_min = 0.0,即最小的定点值0来表示浮点0;
- 全为负:encoding_max = 0.0,即最大的定点值255来表示浮点0;
- 有正有负:如输入浮点范围为[-5.1, 5.1],
- encoding_min = -5.1,encoding_max = 5.1;
- encoding区间10.2,step size=10.2 / 255 = 0.04;
- 先不表示0,因为定点step_idx区间是[0, 255],观察在给定最小值+步长情况下,即encoding_min+step_idx*step_size的值与0最近的值的step_idx,与0最近的step_idx必然一正一负,发现刚好步数step_idx为127和128时,分别是-0.02与+0.02与0最近。 因为这俩数(的绝对值)与0一样近,(127与128这两个数)选哪个作为0都可以,那就选小的吧,那么step_idx即第127步就是0点,那么这样一来,最小值和最大值就都被拉低了0.02与0的差即0.02,新的encoding_min=-5.12,encoding_max=5.08;
- 对输入浮点值定点量化:quantized_value = round(255 * (float_val - encoding_min) / (encoding_max - encoding_min)),这样量化的值被夹在[0, 255],考虑两端的情况:
- 当遇到最小值-5.10时,quantized_value = round(255 * (-5.10 + 5.12) / (5.08+5.12)) = 1.0;
- 当遇到最大值+5.10时,quantized_vlaue = round(255 * (5.10 + 5.12) / (5.08+5.12)) = 256,卧槽溢出了????!!!(这里有点懵,我想可能溢出就会用255或0强制表示吧,所以SNPE文档中有下面一条限制??我猜应该是这样);
- 总之量化值都是介于0到255之间;
- 输出:浮点的定点结果,encoding_min和encoding_max。
5.2 例子:量化与反量化
给定输入input_values = [-1.8, -1.0, 0, 0.5]。现根据上面算法描述做定点量化,并之后恢复回原浮点。
5.2.1 量化
- encoding_max := 0.5,encoding_min := -1.8;
- range := encoding_max - encoding_min = 2.3,step_size := range / 255 = 0.009019607843137253;
- 有正有负,根据encoding_min + step_idx * step_size,step_idx∈[0, 255]。观察到距离0最近的step_idx分别为:
- step_idx为199时:zero_diff_neg = -1.8+199*2.3/255 = -0.005098039215686301;
- step_idx为200时:zero_diff_pos = -1.8+200*2.3/255 = 0.003921568627450744;
- 从绝对值来说,step_idx为200时距离0更近,即abs(zero_diff_neg) > abs(zero_diff_pos)。那么就选200这个step_idx作为定点与浮点0相对应的点,zero_step_idx := 200;
- 修正encoding_max与encoding_min,根据step_idx=200时的zero_offset = 0.003921568627450744,对二者修正,都往右移:
- encoding_min := encoding_min + zero_offset = -1.7960784313725493;
- encoding_max := encoding_max + zero_offset = 0.5039215686274507; 注:这里SNPE文档中,算的zero_offset=-0.003921568627450744,是负数,怀疑是否是SNPE搞错了正负号。
- 量化输入为定点,根据公式quant_value = round( 255 * (float_val - encoding_min) / (encoding_max - encoding_min) ):
- quant_value(-1.8) = -0.0;
- quant_value(-1.0) = 88;
- quant_value(0) = 199;
- quant_value(0.5) = 255;
- 输出量化结果和encoding_min与encoding_max。
5.2.2 反量化
输入:
- 量化的定点值:[0, 88, 199, 255];
- encoding_min = -1.7960784313725493;
- encoding_max = 0.5039215686274507;
- step_size = 0.009019607843137253。
反量化公式,根据量化公式quant_value = round( 255 * (float_value - encoding_min) / (encoding_max - encoding_min) )推导出来float_value。
反量化公式即:float_value = quant_value * (encoding_max - encoding_min) / 255 + encoding_min;
则有反量化结果:
- float_value(0) = -1.7960784313725493;
- float_value(88) = -1.0023529411764711;
- float_value(199) = -0.0011764705882355564;
- float_value(255) = 0.5039215686274505。
5.2.3 误差分析
结果汇总表:
| 输入浮点 | 定点 | 反量化 | (反量化与输入)绝对误差abs_error | 误差占区间比例(encoding_max与encoding_min的区间)error_rate |
|---|---|---|---|---|
| -1.8 | 0 | -1.7960784313725493 | 0.003921568627450744 | 0.0017050298380220628 |
| -1.0 | 88 | -1.0023529411764711 | 0.0023529411764711128 | 0.0010230179028135275 |
| 0 | 199 | -0.0011764705882355564 | 0.0011764705882355564 | 0.0005115089514067637 |
| 0.5 | 255 | 0.5039215686274505 | 0.003921568627450522 | 0.0017050298380219663 |
| encoding_min | -1.7960784313725493 | |||
| encoding_max | 0.5039215686274507 | |||
| encoding_range | 2.3 | |||
| step_size | 0.009019607843137253 | |||
| (反量化与输入)绝对误差abs_error | abs(input_float_val - dequant_val) | |||
| 误差占区间比例(encoding_max与encoding_min的区间)error_rate | abs_error / encoding_range |
5.3 量化模式
支持两种8bit定点的模式,主要区别在于量化参数的选择。
- 第一种方式,默认量化方式,即前面算法描述中提到的。特点是使用数据真实的最大最小来做量化,有一个最小区间阈值0.01,0要被精确表示(而且也会影响到对最大最小值的修正);
- 第二种方式,增强量化方式,给量化命令snpe-dlc-quantize传入use_enhanced_quantizer从而调用。该模式会计算出一组更好的量化参数,而且也要求最小范围range阈值为0.01,确保0被精确量化(类似默认量化方式)。但从表象上来说也有几点不同:
- 该方式选出的最大最小值,可能和默认量化方式的不同;
- 设置的range范围可能权重或者激活值并没不会出现在这个范围内;
- 更适用于具有长尾性质的权重或者激活值(如大多数权重位于-100到1000之间,但是有几一些值远远小于-100,大于1000)。在某些情况下,这种长尾值因为被忽略掉(比用真实最大最小计算量化范围的量化方式,如默认方式),有更好的分类精度。
但第二种方式的计算精度,在某些长尾情况下,比简单直接使用真实最大最小的情况要好。
5.4 量化影响
量化对模型对DSP是必不可少,因为DSP只能跑定点模型,而定点模型又会影响到精度,某些模型量化效果不好甚至出现错误结果。根据SNPE文档,评估量化模型的指标有:
- Mean Average Precision:
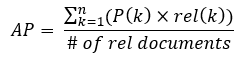 ,这里不具体展开;
,这里不具体展开; - Top1误差:概率最高的类别不是真实类别;
- Top5误差:真实类别不在概率前5类别中。
5.5 新卷积模块设计
因为int8精度低的问题,高通官方提出一种方法:A Quantization-Friendly Separable Convolution for MobileNets,一种新的MobileNet卷积核心模块,如下图。
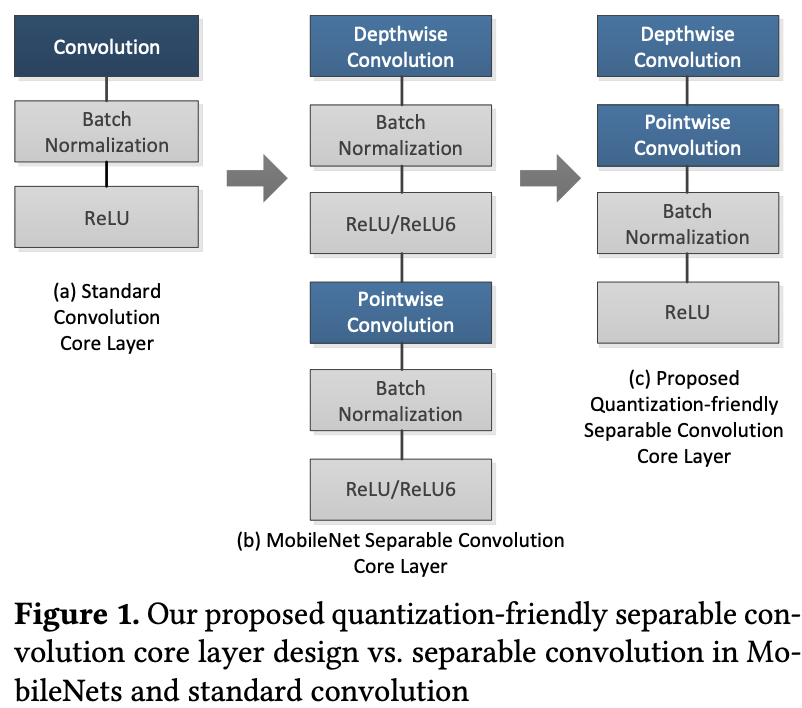
上图分别表示经典标准的卷积模块、MobileNetV1原文中的Depthwise和Pointwise卷积,以及作者提出的卷积模块。效果上最好的架构是下图中的最后一个,也是上图第三个Top1分类精度为68.3%。
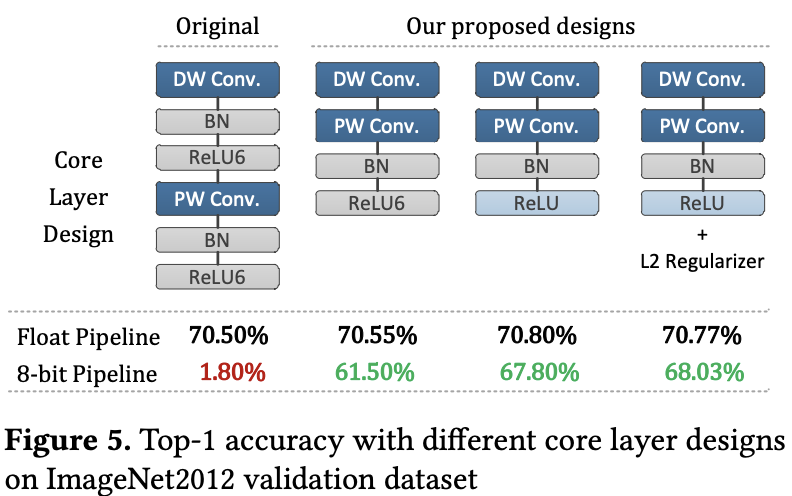
设计出如上的结构,也是基于作者实验得到的一些结论:BatchNorm和ReLU6操作是MobileNetV1的IN8精度损失的主要原因,因而作者移除了所有Depthwise Conv中的BatchNorm以及将ReLU6换为ReLU。
5.6 ReLU6
参考github上ReLU6的正向计算实现:out[i] = min( max(x[i], 0)+negative_slope*min(x[i], 0), 6 ),relu6一般在低精度运算中使用,尤其移动端设备。和relu相比,relu6的输出被限制在了一个固定区间内,根据tensorflow的文档说明:
This is useful in making the networks ready for fixed-point inference. If you unbound the upper limit, you lose too many bits to the Q part of a Q.f number. Keeping the ReLUs bounded by 6 will let them take a max of 3 bits (upto 8) leaving 4/5 bits for .f this used to be called a “hard sigmoid” paper:Convolutional Deep Belief Networks on CIFAR-10
在stackoverflow上的一则关于Why the 6 in relu6?问题中,有人回答道,AlexNet的作者Alex Krizhevsky在其一篇论文Convolutional Deep Belief Networks on CIFAR-10中解释说:
Our ReLU units differ from those of [8] in two respects. First, we cap the units at 6, so our ReLU activation function is y = min(max(x, 0), 6).
In our tests, this encourages the model to learn sparse features earlier. In the formulation of [8], this is equivalent to imagining that each ReLU unit consists of only 6 replicated bias-shifted Bernoulli units, rather than an infinute amount. We will refer to ReLU units capped at n as ReLU-n units.
注:参考[8]是Geoffrey Hinton为第二作者ICML2010的文章:Rectified Linear Units Improve Restricted Boltzmann Machines。
表明ReLU6是为定点推理设计的,通过限制上限让值域在[0, 6],2^3=8,则0-6占了7个,可以实现低bit模型量化,如无符号int2定点,或有符号int3。从下图其ReLU6的函数图像上,可以看出类似Sigmoid(x) = 1 / (1+e^(-x)),sigmoid函数图象是值域为(0, 1)的S型曲线,与ReLU6作为对照,ReLU6位于[0, 6)的输入区间是线性的,而输入大于等于6时的值域为6,因此也被称为Hard Sigomid。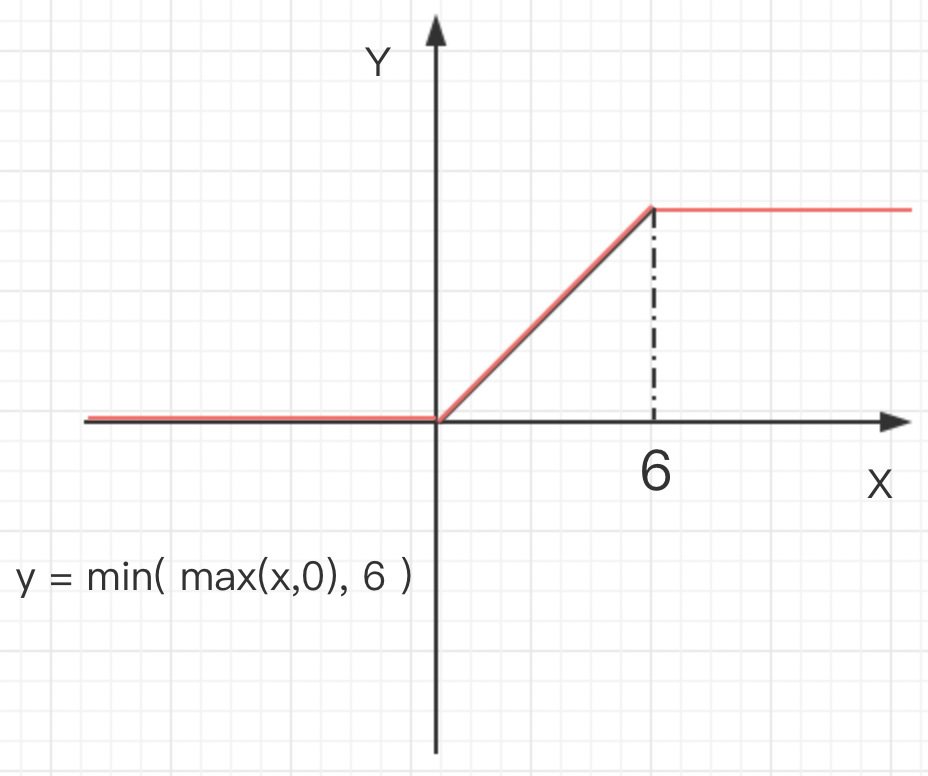
再就是从实验结果来说,ReLU6在训练阶段会早早地学到稀疏化特征,不知是针对当前这一层还是最后一层的feature map。对于提到的伯努利units这块,对原文翻译是:每个ReLU6单元只包含6个偏移贝努利单元,而不是一个无限量,我们将RELU单元称为RELU-N单元,上限为N。我对其理解是伯努利单元是说原本是ReLU,后面是无限量,即max(x, 0),但是ReLU6使用6这个上限将其拆分成3截,说到这里,就提一下伯努利分布(Bernoulli distribution)又名两点分布或0-1分布,伯努利实验是只有两种可能结果的单次随机试验,那么我对伯努利单元的理解就是从原本的max(x, 0)的二选一,对其进行6个单位的偏移,即公式中的max(x, 6),即伯努利单元。
一位群友解释了6 replicated bias-shifted Bernoulli units:
relu(x) = max(0, x),而relu6(x) = min(max(0, x), 6),与relu不同的relu6并非上界是无限量,而是上界限定为6,因为Bernoulli units 是 0-1分布,那么6 replicated bias-shifted Bernoulli units 就是 min(max(0, x), 1) + min(max(1, x), 2) + … + min(max(5, x), 6) 。
6个函数的叠加(6 replicated),每个函数的上下界差1,而下界不再为0,所以称为bias-shifted。
但是我对着6个叠加的函数分别画出图像如下,累加起来结果并不是relu6,比方就看[0,1]区间内,x=0.5时,y = x+1+2+3+4+5 = 15.5。
然后和那位同学又讨论了下,应该是对原relu函数重复6次,大概验证了下是正确的。