Peripateticism
Yuens' blog
高级凸优化
这部分是MXNet第六课的高级凸优化的学习记录,包含基本的凸函数性质说明,主要讲解了收敛率以及后面的高级优化算法,包括动量法、Adagrad、AdaDelta、RMSProp、Adam。重点介绍了一个由动量法引入的EMA(Exponential Moving Average,即指数平均数指标),在包括Adam等等优化算法都有它的身影。
1. 凸函数性质
好了,我们先从凸函数的性质讲起,凸函数的一般性质是二阶导数大于等于零,即
\[f''(x) \geq 0\]简单补充:
- 一阶导大于0,则递增;一阶导小于0,则递减,一阶导等于0,则不增不减;
- 一阶倒数是自变量的变化率,二阶倒数是一阶导数的变化率。也就是一阶导数变化率的变化率;
- 连续函数的一阶导数就是相应的切线斜率;
- 二阶导数可以反应图像的凹凸。二阶导数大于0,图像为凹,二阶导数小于0,图像为凸,二阶导数等于0,不凸不凹。
- 结合一阶、二阶导数可以求函数的极值。当一阶导数等于0,而二阶导数大于0时,为极小值;当一阶导数等于0,而二阶导数小于0时,为极大值点,当一阶导数、二阶导数都等于0时,为驻点。
如果整个函数可行域是实数的话,问题就是一个凸优化问题。这里有一个收敛率的问题,有两个收敛率的公式:
-
亚线性收敛(Sub-linear rate of convergence) \(f(x^{(t)}) f(x^*) \leq O(\frac{1}{\sqrt(t)})\)
-
线性收敛(linear rate of convergence):如果被这个bound住,叫做线性收敛。
\[f(x^{(t)}) f(x^*) \leq O(\alpha^{t}), \alpha \in (0,1)\]
两个可以合起来观察bound的层级关系:
\[f(x^{(t)}) f(x^*) \leq O(\frac{1}{\sqrt(t)}) \leq O(\alpha^{t}), \alpha \in (0,1)\]要说两点:
- 随着$t$增加,右边越来越小,会越来越逼近$x$的最优值$ f(x^*)$(最优解)。
- 两个收敛率是有优劣之分,sub-linear比linear收敛要更慢一些(下面是两个函数的plot的结果)。
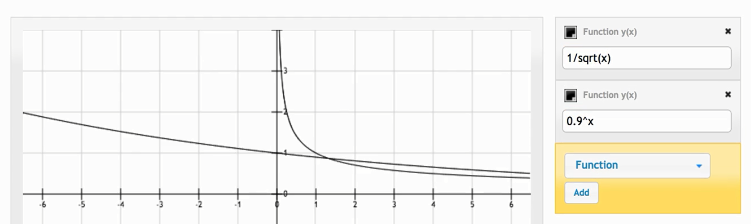
这个看着不是很明显,可以把横轴弄长一些:
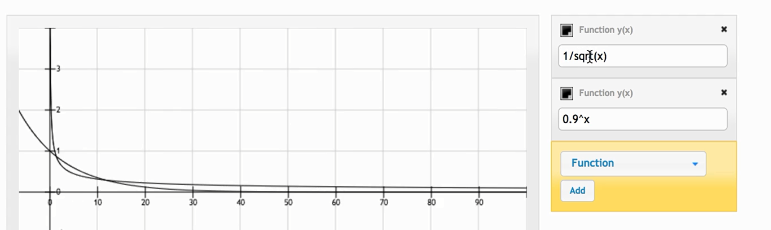
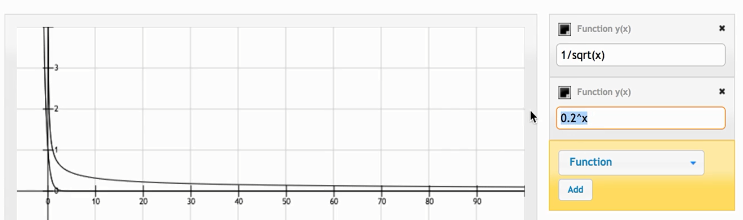
我们也可以把底数变大,在观察一下(会发现$0.2^x$下降的更快):
2. 梯度下降
在凸函数这一设定下,不需要decay learning rate,也是可以慢慢收敛的。
\[E\bigtriangledown f_i(x) = \frac{1}{n}\sum_{i=1}^{n}\bigtriangledown f_i(x)\]但是随机梯度下降(SGD)有个问题,因为不像梯度下降(Gradient Descent)是真实的梯度,随机梯度下降是根据一个样本估计的梯度(包括mini-batch Gradient Descent,是根据batch size个样本来估计真实梯度的)。比方整体样本是1000个样本,用SGD每次都会用一个样本估计真实的梯度,这样会带来一定的方差的,但若是梯度下降(用所有样本来计算梯度,是真实梯度),那随机梯度怎么收敛?是通过对学习率进行decay进行的,这样可强行降低方差(variance),这个decay就体现在下面公式中的$\eta$,他会乘以梯度,但这一decay学习率,学习率越来越小(步幅变小),会造成随时间收敛变慢。
\[E \eta \bigtriangledown f_i(x) = \frac{1}{n}\sum_{i=1}^{n}\bigtriangledown f_i(x)\]由于自我衰减学习率的存在,实际上我们拿到的的亚线性的收敛(sub-linear rate convergence,$f(x^{(t)}) f(x^*) \leq O(\frac{1}{\sqrt(t)})$),也就是说收敛的过程要比真实梯度的梯度下降要慢很多。以上仅适用于凸优化这一前提的。在非凸优化的情况比如深度学习下,即便decay学习率是没什么问题的。
2.1 weight decay
紧接着,用3个案例来说明学习率衰减对收敛的影响。
不decay学习率,batch size=1(随机梯度下降)的情形下,variance变化比较大(抖动厉害),这里用的线性回归(梯度为凸函数)学习率没有衰减,最终难收敛。
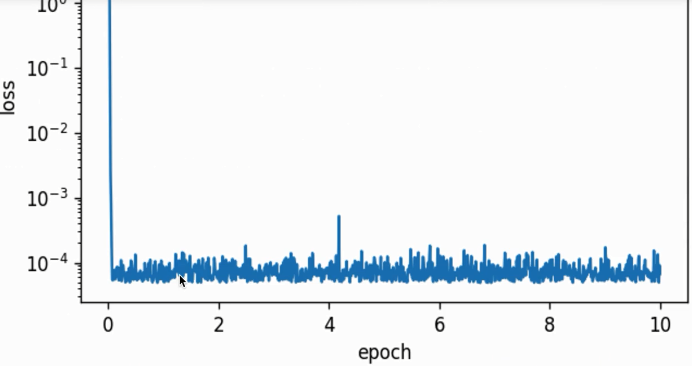
不decay学习率,batch size为整个训练集(梯度下降)的情形下,variance变化平稳,下降过程稳定,最终参数结果接近真实值(且快速收敛):
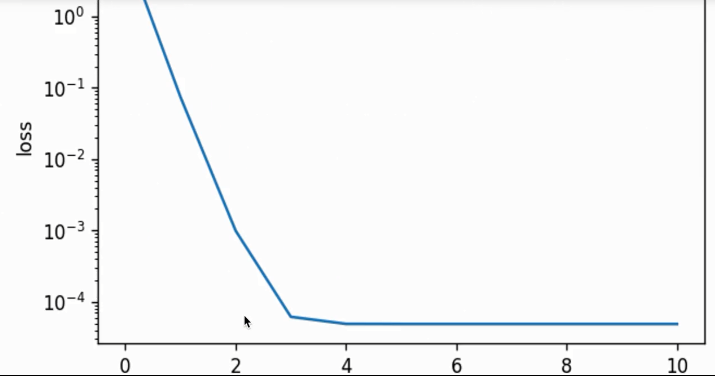
lr decay=0.1,batch size=1,第二个epoch开始衰减,整个过程一开始variance较大但后面稳定,且参数的结果收敛了没再变化:
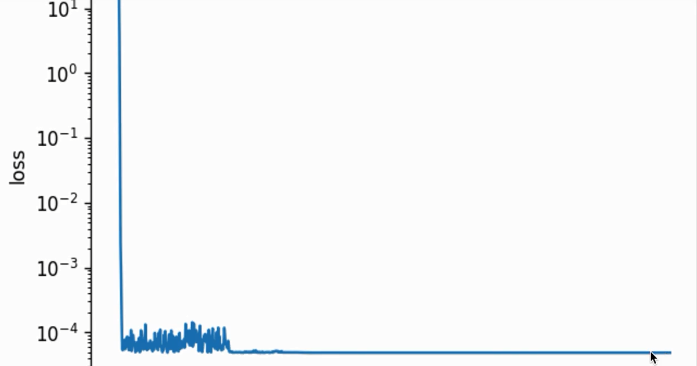
虽然上面不严谨(用肉眼观察),但能体现出学习率衰减(learning rate decay)对随机梯度或者批量随机梯度造成的高方差问题有一定弱化。
3. 理解梯度
假设有二元二次函数:$f(x_1, x_2) = x_1^1 x2 + 3e^{x_2}$。要计算这个函数的梯度,因为是有两个($x_1$和$x_2$),需要分别计算梯度:
\[\begin{bmatrix} \frac{\partial f}{\partial x_1} \\ \frac{\partial f}{\partial x_2} \end{bmatrix} = \begin{bmatrix} 2x_1x_2 \\ x_1^2 + 3e^{x_2} \end{bmatrix} = \begin{bmatrix} 4 \\ 1+3e^2 \end{bmatrix}\]首先把$x2$当做常数计算$x_1$的偏微分(第一行),再将$x_1$当做常数计算$x_2$的偏微分(第二行)。我们假设$x_1=1, x_2=2$计算此时的梯度,结果为$\begin{bmatrix} 4 \ 1+3e^2\end{bmatrix}$。
4. 梯度方向
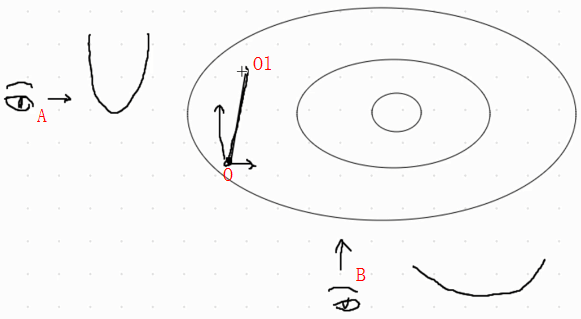
梯度下降是在找下降速度最快的方向,假设初始位置在O下一步会走到O1这个位置,如果从角度A看的话,可以看到更窄弯的更快的角度,如果在角度B看,会看到的是更宽弯的更慢的。
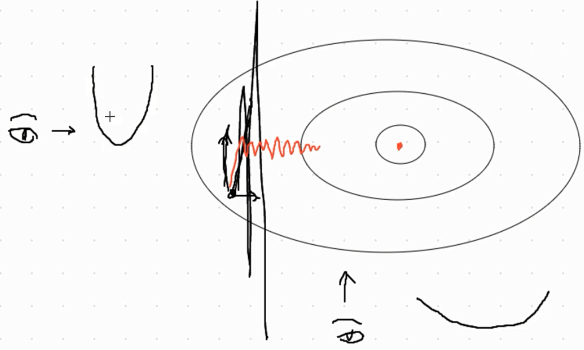
从O出发会往下降速度最快的方向,所以梯度下降会朝着O1这个位置走。但若学习率比较大,会造成竖直方向over-shot的问题(看黑色的粗线,导致发散或者难以收敛的问题 ),那么我们是否需要将学习率设置更低一些呢?但是设低也会导致一个问题:走的很慢(观察红线)而且越来越慢,一点点的去逼近最小值(最优值)。
补充:梯度一阶收敛,二阶收敛方法有牛顿法。二阶的收敛方法在凸优化中常用,但数据量很大且每个epoch/iteration中cost会非常高,在深度学习这样非凸优化中会有很多问题(比方鞍点问题),像牛顿法这样的二阶优化算法也比较难以解决这些问题。
5. 动量法(momentum)
对于走的zigzag这样锯齿状的线条(over-shot),为了解决SGD这些问题(还有收敛越来越慢),就有人提出了动量法。
不过首先,我们先引入一个叫做velocity-速率这一变量:
\[\overrightarrow{v} := \gamma \overrightarrow{v} + \eta \bigtriangledown f_\beta (\overrightarrow{x})\]这一公式中$ \eta \bigtriangledown f_\beta (\overrightarrow{x})$指的是对小批量sample做的梯度然后求平均的梯度,其中$\eta$是学习率。
\[\overrightarrow{x} := \overrightarrow{x} - \overrightarrow{v}\]$x$是模型参数,如果上面第一个公式中$\gamma=0$的话,那么得到的$\overrightarrow{x} := \overrightarrow{x} - \overrightarrow{v} = \overrightarrow{x} - \eta \bigtriangledown f_\beta (\overrightarrow{x}) $就是一个随机梯度下降。那么这个$\gamma$有啥意义呢?
其实,\(\overrightarrow{v} := \gamma \overrightarrow{v} + \eta \bigtriangledown f_\beta (\overrightarrow{x})\) 可以多写一步,稍作变化变成下面这样:
\[\overrightarrow{v} = \gamma \overrightarrow{v} + (1-\gamma) \frac{\eta}{(1-\gamma) } \bigtriangledown f_\beta (\overrightarrow{x})\]5.1 指数平均数指标
其实这个形式是一个优美的公式的EMA(Exponential Moving Average,EMA)格式:
\[y^{(t)} = \gamma y^{(t-1)} + (1-\gamma) x^{(t)}\]这个动量法可以和这个EMA的格式是吻合的,说到这个EMA格式,需要说到的是最近虚拟货币的交易例子,可以看以太币对美元的price chart。在图表的设定有一个Overlay参数,可以选择EMA12和EMA26,因为抖动曲线非常大,想要抓住市场趋势,可以用EMA这个东西来smooth这个波动的走势折线,来更好抓住虚拟货币的走势。
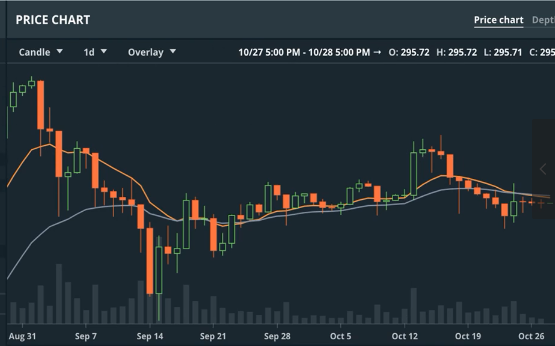
可以看到平滑后的走势图(上面绿色和红色线条分别是EMA12和EMA26的曲线)。再把这个EMA的公式拉出来,我们可以把这个公式展开写出来进一步观察:
\[y^{(t)} = \gamma y^{(t-1)} + (1-\gamma) x^{(t)}\]比方我们从$t=20, \gamma=0.95$开始展开写:
\[\begin{align}y^{(20)} & = 0.05 x ^{20} + 0.95y^{(19)} \\ & =0.05 x^{20} + 0.05 \cdot 0.95 x^{(19)} + 0.95^{2} y^{(18)} \\ & = \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots + 0.05 \cdot 0.95^2 x^{(18)} + 0.05 \cdot 0.95^3 \cdot x^{(17)} + \dots \end{align}\]这个20实际上是对过去的时刻,做一个指数加权的平均,这个指数加权是越近对应的weight越高。因为对过去做平均,随着越来越远重要性越不重要。一直到$0.95^{20}$,可以简单估算一下大概等于$\frac{1}{e}$,大概$0.36$左右:$0.95^{20} \approx \frac{1}{e} \approx 0.36$。也可以写成下面的格式:
\[\varepsilon^{\frac{1}{1-\varepsilon }} \approx \frac{1}{e}\]这里有一个很有意思的地方,这里有一个收敛的threshold,大家会觉得如果小于这个0.36的时候,后面的东西就不重要了(不看了)。
这里$\gamma=0.95$,那就有$\frac{1}{1-\gamma} = 20$,相当于对过去20个数做了EMA这样一个指数加权的平均(越近weight越高),如果$\gamma=0.9$,就有$\frac{1}{1-\gamma}=10$,相当于对过去10天(10个数)做了平均的估算。但是到底对过去多少次来做估算,就看$\frac{1}{1-\gamma}$这个就好了。
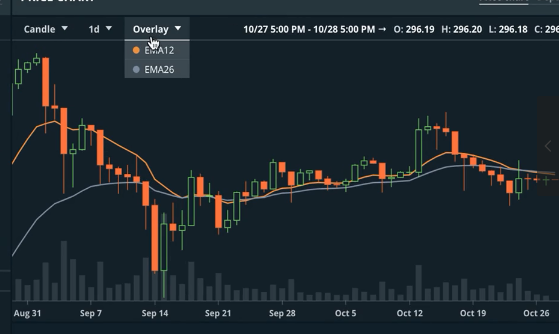
EMA12和EMA26也就是对过去12天和26天做平滑平均(指数加权平均)。在后面这个EMA的格式我们会反复讲到。其实动量也可以理解为:对$\frac{\eta}{1-\gamma} \bigtriangledown f_{\beta} (\overrightarrow{x})$来做EMA,因为我们把动量$\overrightarrow{v}$写成了EMA的形式:
\[\begin{eqnarray} \overrightarrow{v} & = \gamma \overrightarrow{v} + \eta \bigtriangledown f_\beta (\overrightarrow{x}) \\ & = \gamma \overrightarrow{v} + (1-\gamma) \frac{\eta}{(1-\gamma) } \bigtriangledown f_\beta (\overrightarrow{x}) \end{eqnarray}\]把估计完的梯度$\overrightarrow{v}$(因为若是随机梯度或者小批量梯度下降,总之不是full batch的梯度下降的话,梯度的计算都是用小于所有训练样本数的样本来更新梯度,所以说是估计的梯度)丢到我们的模型参数$\overrightarrow{x} := \overrightarrow{x} - \overrightarrow{v}$的计算公式,即梯度下降(或者随机梯度下降)的公式中。
5.2 动量法的感性认识
通过EMA我们实际上在训练的过程中可以把overshot的一部分给平滑掉,虽然不是很完美地抵消掉,但是可以在做一正一反的更新过程中用指数加权平均抵消掉一部分。

因此我们可以把学习率设置的大一些,在一开始可能有over-shooting的左右,但由于EMA一正一反的抵消作用,在即使一开始学习率比较大哪怕初始位置点不好的情况下,依然能向着最优值收敛。以上也是动量法最直观的作用。
5.3 另一种理解方式
我们的动量法写成:
\[\begin{eqnarray} \overrightarrow{v} & = \gamma \overrightarrow{v} + \eta \bigtriangledown f_\beta (\overrightarrow{x}) \\ \overrightarrow{x} & = \overrightarrow{x} - \overrightarrow{v} \end{align}\]其中对模型参数$\overrightarrow{x}$做迭代,我们假设$\bigtriangledown f_\beta (\overrightarrow{x})$为$\overrightarrow{g}$,那么就有以下(同时,根据规律可以算出$\overrightarrow{v_{inf}}$):
\[\begin{eqnarray} \overrightarrow{v_1} &= \eta \overrightarrow{g} \\ \overrightarrow{v_2} &= \eta \overrightarrow{v_1} + \eta \overrightarrow{g} = \eta \overrightarrow{g} (\eta + 1) \\ \overrightarrow{v_3} &= \dots \dots \dots = \eta \overrightarrow{g} (\eta^2 + \eta + 1) \\ \overrightarrow{v_{inf}} &= \frac{\eta \overrightarrow{g}}{1-\gamma} \end{eqnarray}\]最后是根据无穷等比数列得到的规律的结果。
我们以上讲的都是又cancel out(抵消)学习率的情况,但是可以假设有一个情况:梯度一直朝着最优的方向走(走了一个直线),而且每次梯度都是一样大的。比方$\gamma=0.99$,那么有$1-\gamma=0.01$,$\frac{1}{0.01}=100$相当于当前走的这一步被放大了$100$倍,换句话说,如果不存在zigzag走的,那么只是朝着同一方向走(perfect aligned),那么迭代到$\overrightarrow{v_{inf}}$次数时,$\eta \overrightarrow{g}$被放大了$100$倍。
也就是说,实际上$\frac{1}{1-\gamma}$才是能给我们带来insight的参数。如果$\gamma=0.98$,就是当前步被放大了50倍;如果$\gamma=0.9$,就是当前这步被放大了10倍。
5.4 代码实现
再列出公式:
\[\begin{eqnarray} \overrightarrow{v} &= \gamma \overrightarrow{v} + \eta \bigtriangledown f_\beta (\overrightarrow{x}) \\ \overrightarrow{x} &= \overrightarrow{x} - \overrightarrow{v} \end{align}\]从公式直接翻译来的代码:
def sgd_momentum(param, vs, lr, mom, batch_size):
for param, v in zip(params, vs):
v[:] = mom * v + lr * param.grad / batch_size
param[:] -= v
代码中的mom(也就是momentum的简写)也是就是公式中的$\gamma$。
5.5 调参说明
-
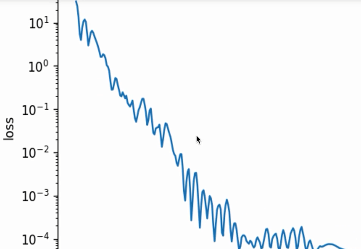
$\gamma=0.9$时,可以看到(下图)整体走势还是比较猛的,相当于当前的梯度被放大了10倍。
-
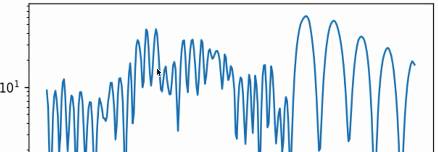
$\gamma=0.99$时,会放大100倍,会走的更猛(下图)。
-
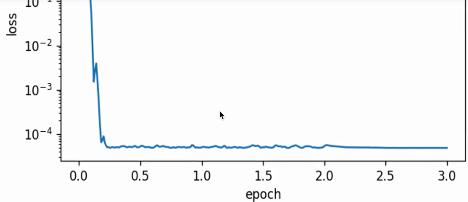
$\gamma=0.5$时,会放大2倍,此时就很缓和了(下图)。
以上可以看到,优化参数背后有的数学道理,对应不同参数的insight,来更好理解地在观察到不同实验现象去调整参数。
6. Adagrad
之前有一个经典的模型是用Adagrad训练的(好像是google cat还是imgnet哪次比赛中),总之在那阵子很流行,比较有趣的地方在于学习率是adaptive的。
其实先前我们所讲的无论是梯度下降、随机梯度或者动量法,其实都有一个问题:共同的一个issue——在同一时刻,对于参数每个元素都是用的是相同的学习率。比方损失函数为$L$,参数为一个多维向量$[x_1, x_2]^{T}$时,该向量中每个元素在更新时都是用相同的学习率,例如学习率为$\eta$时的梯度下降:
\[\begin{eqnarray} x_1 &:= x_1 - \eta \frac{\partial L}{\partial x_1} \\ x_2 &:= x_2 - \eta \frac{\partial L}{\partial x_2} \end{eqnarray}\]其中的元素$x_1$和$x_2$都是用相同的学习率$\eta$来自我迭代。如果让$x_1$和$x_2$使用不同的学习率自我迭代呢?
Adagrad就是一个在迭代中不断自我调整学习率,并让模型参数中每个元素使用不同学习率的。不过在介绍该算法前,需要先介绍一些按元素操作的例子,以$x = [4,9]^T$为例:
- 按元素相加:$x +1 = [5, 10]^T$
- 按元素相乘:$x \odot x = [16, 81]^T$
- 按元素相除:$72/x = [18, 8]^T$
- 按元素开方:$\sqrt{x} = [2, 3]^T$
介绍完按元素操作,我们可以来讲一下adagrad具体流程:
\[\begin{eqnarray} \overrightarrow{s} & = \overrightarrow{s} + \overrightarrow{g} \odot \overrightarrow{g} \\ \overrightarrow{g}^{'} & = \frac{\eta}{\sqrt{\overrightarrow{s} + \epsilon} } \odot \overrightarrow{g} \\ \overrightarrow{x} & = \overrightarrow{x} - \overrightarrow{g}^{'} \\ \end{eqnarray}\]- 公式1:$\overrightarrow{s}$是一个不断累加的公式,$\overrightarrow{g}$是模型参数为$x$时的梯度$\bigtriangledown f_{\beta} (\overrightarrow{x})$,同时$\odot$是按照元素相乘的操作;
- 公式2:真正使用的梯度是需要做一个修改的$\overrightarrow{g}^{‘}$(注意是带了一撇的$\overrightarrow{g}$),同时$\overrightarrow{s}$会被丢到开方里,再加入一个$\epsilon$来保证数值稳定性(一般我们会把$\epsilon$设置为一个比较小的常数,如adagrad常用的$\epsilon = 10^{-7}$),再按照元素相乘$\overrightarrow{g}$。其中$\eta$是初始学习率。
刚开始的时候,$\overrightarrow{s}=0$,随着梯度$\overrightarrow{g}$的不断累加,也就是梯度$\overrightarrow{g}$按照元素的不断平方,丢到新的梯度$\overrightarrow{g}^{‘}$的计算公式的分母中,在维持了数值稳定性后(也就是分母加上$\epsilon$),再乘以$\eta \odot \overrightarrow{g}$,这部分也相当于随机梯度下降(或者小批量梯度下降)中的学习率乘以梯度。只不过adagrad在原本的梯度下降(或小批量梯度下降)前面多了一项$\frac{1}{\sqrt{\overrightarrow{s} + \epsilon}}$,如果没有这一项就是(随机)梯度下降。Adagrad只是不断地累加按元素梯度的平方,加上数值稳定性项$\epsilon$,后开方。
那这有什么insight,首先一个就是$\overrightarrow{g}$去descent迭代时,每次前面的学习率$\frac{1}{\sqrt{\overrightarrow{s} + \epsilon}}$可能就不太一样了:每个元素都有其自己的各自分别的学习率。但由于这一步的操作,$\overrightarrow{g}$的第一个分量元素比较大时,会导致这一步在计算新的$\overrightarrow{g}^{‘}$的第一个元素时,因为分母$\frac{1}{\sqrt{\overrightarrow{s} + \epsilon}}$的存在,第一个元素的学习率下降会慢。相反,若有$\overrightarrow{g}$的第二个元素比较小,$\overrightarrow{s}$的第二个元素增加的会比较小,会造成$\overrightarrow{g}^{‘}$的第二个元素计算会变大,第二个元素的学习率下降会快。
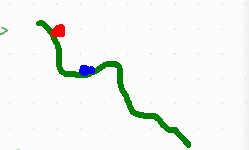
在adagrad这篇文章出现时,解决的是凸优化的问题。SGD的学习率衰减是有利于收敛的,但深度学习中是否收敛就不好说了。若初始化位置不好,比方说下面这样:初始位置不好(下图红点),因为学习率decay的太快,慢慢会走到蓝色点的位置,失去了更加宽广的世界。
adagrad因为$\overrightarrow{s}$会不断累加$\overrightarrow{s} = \overrightarrow{s} + \overrightarrow{g} \odot \overrightarrow{g}$,会导致学习率会不断衰减$\overrightarrow{g}^{‘} = \frac{\eta}{\sqrt{\overrightarrow{s} + \epsilon} } \odot \overrightarrow{g} $。说白了就是有时运气好,初始化位置好可以拿到一个不错的performance,但有时会运气不好(初始化位置不好),就糟糕了。
6.1 代码实现
首先还是列出公式:
\[\begin{eqnarray} \overrightarrow{s} & = \overrightarrow{s} + \overrightarrow{g} \odot \overrightarrow{g} \\ \overrightarrow{g}^{'} & = \frac{\eta}{\sqrt{\overrightarrow{s} + \epsilon} } \odot \overrightarrow{g} \\ \overrightarrow{x} & = \overrightarrow{x} - \overrightarrow{g}^{'} \\ \end{eqnarray}\]还有翻译得到的代码:
def adagrad(params, sqrs, lr, batch_size):
eps_stable = 1e-7
for param, sqr in zip(params, sqrs):
g = param.grad / batch_size
sqr[:] += nd.squre(g)
div = lr * g / nd.sqrt(sqr + eps_stable)
param[:] -= div
6.2 Adagrad算法缺点
上面可以看到这个问题的产生是因为$\overrightarrow{s}$会不断累加$\overrightarrow{s} = \overrightarrow{s} + \overrightarrow{g} \odot \overrightarrow{g}$造成的,导致$\overrightarrow{g}^{‘} = \frac{\eta}{\sqrt{\overrightarrow{s} + \epsilon} } \odot \overrightarrow{g} $公式中的分母不断下降。那么怎么解决这个学习率不断decay的问题呢?
7. RMSProp
有两个算法可以解决学习率不断衰减的问题:一个是RMSProp算法(另一个算法是后面会讲到的Adadelta)。RMSProp就是Adagrad基础上略作修改: \(\begin{eqnarray} \overrightarrow{s} & := \gamma \overrightarrow{s} + (1 - \gamma) \overrightarrow{g} \odot \overrightarrow{g} \\ \overrightarrow{g}^{'} & := \frac{\eta}{\sqrt{\overrightarrow{s} + \epsilon} } \odot \overrightarrow{g} \end{eqnarray}\)
把原本有关$\overrightarrow{s}$的不断累加的形式修改为EMA的形式(同时保留模型参数中各自元素自适应学习率的特点)。
7.1 代码实现
def rmsprop(params, sqrs, lr, gamma, batch_size):
eps_stable = 1e-8
for param, sqr in zip(params, sqrs):
g = param.grad / batch_size
sqr[:] = gamma * sqr + (1. - gamma) * nd.square(g)
div = lr * g / nd.sqrt(sqr + eps_stable)
param[:] -= div
7.2 调参说明
当$\gamma=0.9$,相当于对过去的10次数据做EMA,如果我们使用默认的$\gamma=0.9$这个值时候的参数应用到我们当前线性回归的案例中可以看到在loss收敛后,会出现loss再次抖动的情况。换句话说,10次数据,受到local当前这次数据的影响还是有些大。

需要说明的是,再次过程中没有对学习率做decay,且我们使用的学习率是0.03。但当$\gamma=0.9$的时候是对过去10次数据做EMA,可以发现振幅还在,也就是说variance还在而且比较明显。此时如果想要调整让它的loss下降更加平滑,我们可以把$\gamma$调大,比方$\gamma=0.999$,相当于对最近的1000次数据做EMA,得到的结果更加稳定和平滑(如下图)。
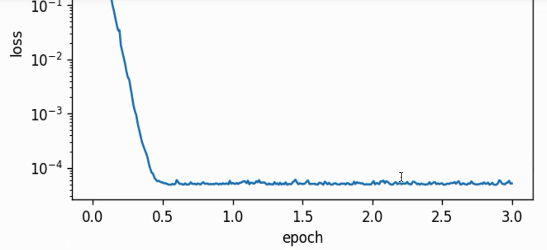
这个实验现象也解释了EMA的insight,其实理解$\gamma$的方式应该从$\frac{1}{1-\gamma}$的值来理解。从最近的$\frac{1}{1-\gamma}$次数据来做EMA,得到的结果肯定也更稳定一些。
8. Adadelta
这个算法和RMSProp一样(对模型参数的每个元素的梯度步幅自适应),可以解决学习率不断衰减的问题,它有个特点:没有学习率参数(更准确来说应该是:不需要手动设置初始学习率参数)。
\[\begin{eqnarray} \overrightarrow{s} & := \gamma \overrightarrow{s} + (1 - \gamma) \overrightarrow{g} \odot \overrightarrow{g} \\ \overrightarrow{g}^{'} & := \frac{\sqrt{ \Delta \overrightarrow{x} + \epsilon }}{\sqrt{\overrightarrow{s} + \epsilon} } \odot \overrightarrow{g} \end{eqnarray}\]可以看到上面Adadelta第一个公式中还是对$\overrightarrow{g} \odot \overrightarrow{g}$做了EMA,之后第二个公式中把第一个公式计算得到的$\overrightarrow{s}$带入第二个公式的分母的根号中,$\epsilon$依旧是为了维持数值稳定性而引入的一个常数。只不是引入了一个$\Delta \overrightarrow{x}$。需要注意的是我们所有向量初始化的值都是元素全部为0的张量。并做如下$\overrightarrow{g}^{‘}$按元素平方的指数加权移动平均(EMA):
\[\Delta x := \rho \Delta x + (1 - \rho) \overrightarrow{g}^{'} \odot \overrightarrow{g}^{'}\]需要注意的是,和前面的方法不同,$\overrightarrow{g}^{‘}$按元素平方前面的系数没有$\eta$,而是被分子$\sqrt{ \Delta \overrightarrow{x} + \epsilon }$所取代,而且分子和分母都是EMA的形式,但有一处不同在于,分子的$\Delta \overrightarrow{x}$是对$\overrightarrow{g}$的平方项做EMA,而分母的$\overrightarrow{s}$是对当前的$\overrightarrow{g}^{‘}$的平方项做EMA。其含义依然是,想通过EMA自适应模型参数各自的学习率,而且在AdaDelta中,我们不需要手动设置初始学习率。
同样的,最后的参数迭代步骤与小批量随机梯度下降类似,只是这里梯度前的学习率已经被调整过了。
8.1 代码实现
def adadelta(params, sqrs, delta, rho, batch_size):
eps_stable = 1e-5
for param, sqr, delta in zip(params, sqrs, deltas):
g = param.grad / batch_size
sqr[:] = rho * sqr + (1. - rho) * nd.square(g)
cur_delta = nd.sqrt(delta + eps_stable) / nd.sqrt(sqr + eps_stable)
delta[:] = rho * delta + (1. - rho) * cur_delta * cur_delta
param[:] -= cur_delta
上面的代码中sqr[:]和delta[:]分别对应的是两个EMA项。设置$rho=0.9999$,最终的收敛情况是(下面截图没有截好,右边基本上是水平的):

最终迭代出的结果和ground-truth的权重是基本一致的。
9. Adam
MXNet gluon默认提供的优化算法不是SGD(而是Adam了)。Adam是组合了动量法和RMSProp的优化算法。
Adam算法会使用一个动量变量$\overrightarrow{v}$和一个RMSProp中梯度按照元素平方的指数加权移动平均变量$\overrightarrow{s}$,并将它们中的每个元素都初始化为$0$。在每次迭代中,首先计算小批量梯度$\overrightarrow{g}$,并递增迭代次数:
\(t:=t+1\) 然后对梯度做指数加权移动平均并计算动量变量$\overrightarrow{v}$(这里其实抄袭了一个动量法): \(\overrightarrow{v} := \beta_1 \overrightarrow{v} + (1 - \beta_1) \overrightarrow{g}\)
再就是动量的更新公式(这里写成explicit的EMA格式,对梯度中的每个元素做了平方,其实这也是抄袭了RMSProp):
\[\overrightarrow{s} := \beta_2 \overrightarrow{s} + (1 - \beta_2) \overrightarrow{g} \odot \overrightarrow{g}\]这里有一个冷启动的问题,其实这也是EMA(Exponential Moving Average)的一个issue。如果$\overrightarrow{v}$和$\overrightarrow{s}$初始化为零张量的话,那么一开始会被这个零张量拖后腿,每次做参数更新都会和零来做EMA。导致一开始的$\overrightarrow{v}$和$\overrightarrow{s}$的值会比较小。要举的例子还是以太币对美元的走势:
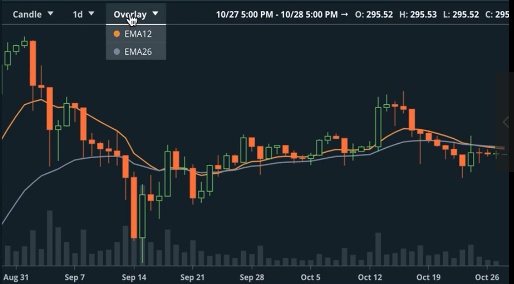
要说的是还是上图的两个走势一个EMA12(红色平滑的走势线)和EMA26(绿色平滑的走势线),能看到两条线一开始都比较低,既然EMA在smooth它,为何不是从上面开始走,而是从下面?这就是有冷启动的问题:一开始做EMA时,被初始时0这个值给拉低了,只能等线warm up后才能更好地模拟真正的波动。
实际在算法中,一开始初始化的$\overrightarrow{s}$和$\overrightarrow{v}$是零张量导致值比较低。为解决冷启动的改进版:
\[\begin{eqnarray} \hat{\overrightarrow{v}} & := \frac{\overrightarrow{v}}{1 - \beta_{1}^t} \\ \hat{\overrightarrow{s}} & := \frac{\overrightarrow{s}}{1 - \beta_{2}^t} \end{eqnarray}\]简单分析一下,上面计算新的$\hat{\overrightarrow{v}}$是用原始的$\overrightarrow{v}$来除以一个$1-\beta_{1}^t$,同样地下面的$\hat{\overrightarrow{s}}$也用类似的方法做偏差的修正。就是在Adam论文中默认得$\beta_1 = 0.9, \beta_2=0.999$。$\beta_1$带来的结果是通过公式$\hat{\overrightarrow{v}} = \frac{\overrightarrow{v}}{1 - \beta_{1}^t}$相当于$v$被放大10倍,但是随着时间$t$越来越,慢慢就不修正它了$\beta^t$会接近于0,分母就基本上接近于1了,$t$越来越大$\hat{\overrightarrow{v}} = \frac{\overrightarrow{v}}{1 - \beta_{1}^t}$就没有修正作用了。后者$\beta_2$相当于$\overrightarrow{s}$被放大了1000倍,其他类似就不赘述了。
我们使用以上偏差修正后的动量变量和RMSProp中梯度按元素平方的指数加权移动平均(EMA)变量,将模型参数中每个元素的学习率通过按元素操作重新调整:
\[\overrightarrow{g}^{'} := \frac{\eta \hat{\overrightarrow{v}}}{\sqrt{\hat{\overrightarrow{s}} + \epsilon}}\]其中,$\eta$是初始学习率,$\epsilon$是为了维持数值稳定性而添加的常数,如$10^{-8}$。和Adagrad一样,模型参数中每个元素都分别有自己的学习率。
同样地,最后的参数迭代步骤与想批量随机梯度下降类似。知识这里梯度前的学习率已经被调整过了:
\[\overrightarrow{x} := \overrightarrow{x} - \overrightarrow{g}{'}\]简单把以上Adam的公式总结一下:
\[\begin{eqnarray} t & :=t+1 \\ \overrightarrow{v} & := \beta_1 \overrightarrow{v} + (1 - \beta_1) \overrightarrow{g} \\ \overrightarrow{s} & := \beta_2 \overrightarrow{s} + (1 - \beta_2) \overrightarrow{g} \odot \overrightarrow{g} \\ \hat{\overrightarrow{v}} & := \frac{\overrightarrow{v}}{1 - \beta_{1}^t} \\ \hat{\overrightarrow{s}} & := \frac{\overrightarrow{s}}{1 - \beta_{2}^t} \\ \overrightarrow{g}^{'} & := \frac{\eta \hat{\overrightarrow{v}}}{\sqrt{\hat{\overrightarrow{s}} + \epsilon}} \end{eqnarray}\]思想主要体现在对$\overrightarrow{v}$和$\overrightarrow{s}$做EMA,并做偏差修正解决冷启动问题。之后将修正后的$\hat{\overrightarrow{v}}$放到$\overrightarrow{g}^{‘}$的分子上作为动量,将$\hat{\overrightarrow{s}}$放到分母$\overrightarrow{g}^{‘}$中做RMSProp(起到模型参数各元素学习率的自适应作用)。总之可以看到Adam就是将动量和RMSProp想法加一起了。以下是将公式翻译的代码:
def adam(params, vs, sqrs, lr, batch_size, t):
beta1 = 0.9
beta2 = 0.999
eps_stable = 1e-8
for param, v, sqr in zip(params, vs, sqrs):
g = param.grad / batch_size
v[:] = betal * v + (1. - beta1) * g
sqr[:] = beta2 * sqr + (1. - beta2) * nd.square(g)
v_bias_corr = v / (1. - beta1 ** t)
sqr_bias_corr = sqr / (1. - beta ** t)
div = lr * v_bias_corr / (nd.sqrt(sqr_bias_corr) + eps_stable)
param[:] = param - div
补充:优化算法的好坏和自己对优化算法的参数的理解有关,这样更有利于调整参数。即使是用SGD跑cifar数据,也能调到state of art的结果。
10. 总结赠诗一首
梯度下降可沉甸,随机降低方差难;
引入动量别弯慢,Adagrad梯方贪;
Adadelta学率换,RMSProp梯方权;
Adam动量RMS伴,优化还需己调参。
注释:
- 梯方:梯度按元素平方
- 贪:因贪婪故而不断累加
-
学率:学习率
- 第一句:梯度下降虽然可以收敛但由于用bsize个样本来估计真实梯度会有一定方差;
- 第二句:小批量梯度下降引入动量(指数加权平均,EMA)后带来了一定抵消,Adagrad的学习率相比梯度下降(SGD,GD,mini-batch GD)有自适应模型参数元素(通过$\overrightarrow{g} \odot \overrightarrow{g} $实现);
- 第三句:(因为Adagrad还有SGD因为lr不断decay的问题引入两个算法,其中之一的)Adadelta没有学习率(不需要手动设置初始学习率),RMSProp(是另一个解决学习率不断衰减的问题,在Adagrad基础上略作修改,把原本有关$\overrightarrow{s}$的不断累加的形式修改为EMA的形式,同时过$\overrightarrow{g} \odot \overrightarrow{g} $保留模型参数中各自元素自适应学习率的特点);
- 第四句:Adam最后结合动量法和RMSProp(优势明显,动量法来方差的减小抵消,RMSProp带来模型参数不同元素的不同学习率和将累加的$\overrightarrow{s}$变为EMA形式不会使得学习率不断衰减)。