Peripateticism
Yuens' blog

子查询的SQL语法
内容参考《李兴华Oracle数据库》的子查询(链接见文末参考),本节主要包括:[toc] 子查询是整个复杂查询的最重要的一个环节,可以这么说,如果不会子查询,相当于工作都没法干。子查询并不是一个新概念,他是一种概念的融合。
所谓子查询,是指在一个查询中嵌入若干个小的查询。给出的语法如下:
SELECT [DISTINCT] * | 列名称 [别名], 列名称 [别名], … | 统计函数, (
SELECT [DISTINCT] * | 列名称 [别名], 列名称 [别名], … | 统计函数
FROM 数据表 [别名], 数据表 [别名], …
[WHERE 条件(s)]
[GROUP BY 分组字段, 分组字段,…]
[HAVING 分组后过滤]
[ORDER BY 字段 [ASC | DESC], 字段 [ASC | DESC], …])
FROM 数据表 [别名], 数据表 [别名], …, (
SELECT [DISTINCT] * | 列名称 [别名], 列名称 [别名], … | 统计函数
FROM 数据表 [别名], 数据表 [别名], …
[WHERE 条件(s)]
[GROUP BY 分组字段, 分组字段,…]
[HAVING 分组后过滤]
[ORDER BY 字段 [ASC | DESC], 字段 [ASC | DESC], …])
[WHERE 条件(s), (
SELECT [DISTINCT] * | 列名称 [别名], 列名称 [别名], … | 统计函数
FROM 数据表 [别名], 数据表 [别名], …
[WHERE 条件(s)]
[GROUP BY 分组字段, 分组字段,…]
[HAVING 分组后过滤]
[ORDER BY 字段 [ASC | DESC], 字段 [ASC | DESC], …])]
[GROUP BY 分组字段, 分组字段,…]
[HAVING 分组后过滤, (
SELECT [DISTINCT] * | 列名称 [别名], 列名称 [别名], … | 统计函数
FROM 数据表 [别名], 数据表 [别名], …
[WHERE 条件(s)]
[GROUP BY 分组字段, 分组字段,…]
[HAVING 分组后过滤]
[ORDER BY 字段 [ASC | DESC], 字段 [ASC | DESC], …])]
[ORDER BY 字段 [ASC | DESC], 字段 [ASC | DESC], …];
关于子查询的时候,个人可以给出一些参考方式,供选择(95%的问题都可以解决):
- 子查询返回单行单列:HAVING、WHERE;
- 子查询返回多行单列:WHERE;
- 子查询返回多行多列:FROM
在SELECT子句中也可出现子查询,但很少这样做,同时所有的子查询出现时,一定要有“()”括号。
1. 在WHERE子句中使用子查询
WHERE的主要功能是控制数据行,那么在WHERE子句中,子查询返回的结果一般是单行单列、多行单列、单行多列数据。
1.1 子查询返回单行单列
1.1.1 范例:统计出所有高于公司平均工资的雇员信息
第一步:应该统计出公司的平均工资,返回的是一个数值(单行单列)
SELECT AVG(sal) FROM emp;
第二步:以上的查询返回单行单列数据,可以直接在WHERE子句中使用
SELECT *
FROM emp
WHERE sal>(
SELECT AVG(sal) FROM emp);
1.1.2 范例:统计出公司最早的雇佣的雇员信息
第一步:要统计出最早的雇佣日期,使用MIN()函数计算
SELECT MIN(hiredate) FROM emp;
第二步:以上的查询返回的是单行单列,所以在WHERE子句中使用
SELECT * FROM emp WHERE hiredate=(
SELECT MIN(hiredate) FROM emp);
1.2 子查询返回单行多列(了解)
1.2.1 范例:统计出公司雇佣最早,工资最低的雇员(问题特殊)
第一步:统计出公司最早雇佣日期和最低的工资,此处正好都是一条数据
SELECT MIN(hiredate), MIN(sal) FROM emp;
第二步:返回单行多列,只能够在WHERE子句里使用
SELECT * FROM emp WHERE (hiredate, sal)=( SELECT MIN(hiredate), MIN(sal) FROM emp);
1.2.2 范例:查询与SCOTT工资、职位相同的雇员信息
第一步:找到SCOTT的工资和职位
SELECT sal, job FROM emp WJHERE ename='SCOTT';
第二步:在WHERE子句中使用以上查询结果
SELECT * FROM emp
WHERE (sal, job)=(
SELECT sal, job FROM emp WHERE ename='SCOTT')
AND ename<>'SCOTT';
1.3 子查询返回多行单列
如果子查询返回多行单列,实际上相当于数据的查询范围,如果要想针对范围查询,则要使用三个查询符号:IN、ANY、ALL。
1.3.1 IN操作
此功能与前面讲的IN是相同的,指的是在指定范围内。
1.3.1.2 范例:使用IN操作
SELECT * FROM emp
WHERE sal IN (
SELECT sal FROM emp WHERE job='MANAGER');
1.3.1.3 范例:也可使用NOT IN不在范围列
SELECT * FROM emp
WHERE sal NOT IN(
SELECT sal FROM emp WHERE job='MANAGER');
此时就有一个需要注意的小问题了:在使用NOT IN的时候子查询中禁止有NULL,否则不会由任何数据返回。
1.3.2 ANY操作,此操作分三种方式
- =ANY:此功能与IN操作完全一样
SELECT * FROM emp
WHERE sal=ANY(
SELECT sal FROM emp WHERE job='MANAGER');
- >ANY:比子查询的最小值要大
SELECT * FROM emp
WHERE sal>ANY (
SELECT sal FROM emp WHERE job=’MANAGER’);
- <ANY:比子查询的最大值要小
SELECT * FROM emp
WHERE sal<ANY(
SELECT sal FROM emp WHERE job=’MANAGER’);
1.3.3 ALL操作,此操作分为两类
- >ALL:比子查询返回的最大值还要大
SELECT * FROM emp WHERE sal>ALL( SELECT sal FROM emp WHERE job=’MANAGER’);
- <ALL:比子查询最小值还要小
SELECT * FROM emp
WHERE sal<ALL(
SELECT sal FROM emp WHERE job=’MANAGER’);
1.3.3.1 范例:要求查询出工资比30部门都高的雇员信息
第一步:找到30部门的工资
SELECT sal FROM emp WHERE deptno=30;
第二步:使用>ALL操作
SELECT * FROM emp WHERE sal>ALL( SELECT sal FROM emp WHERE deptno=30);
对于给定的多行单列查询,只能够利用以上的三个符号完成。
2. 在HAVING子句中使用子查询
如果使用了HAVING子句就意味着进行了分组,而且进行了统计查询。在HAVING中出现的子查询只能够返回单行单列的数据。
2.1 范例:查询出高于公司平均工资的部门编号、平均工资
第一步:计算拿出公司的平均工资
SELECT AVG(sal) FROM emp;
第二步:要在分组后进行过滤
SELECT deptno, AVG(sal)
FROM emp
GROUP BY deptno
HAVING AVG(sal)>(
SELECT AVG(sal) FROM emp);
2.2 范例:查询出平均工资最低的职位信息、人数、平均工资
第一步:找到平均工资最低的职位数据,这个操作需统计函数嵌套。
SELECT MIN(AVG(sal)) FROM emp GROUP BY job;
第二步:统计函数嵌套后无法再出现分组字段,可将以上单行单列结果出现HAVING子句之中。
SELECT job, AVG(sal) FROM emp GROUP BY job HAVING AVG(sal)=( SELECT MIN(AVG(sal)) FROM emp GROUP BY job);
3. 在SELECT子句中使用子查询(了解)
首先明确一点,在SELECT子句之中使用子查询,只有一种情况下使用(而且此种情况完全是自己没事找事):进行行列转置(行变列,列变行)。
3.1 范例:演示一下,别会了
SELECT e.ename, e.job,
(SELECT dname FROM dept WHERE deptno=e.deptno),
(SELECT loc FROM dept WHERE deptno=e.deptno)
FROM emp e;
以上操作没有任何意义,只是概念的解释,能用就不用。
4. 在FROM子句中使用子查询(核心)
FROM子句的主要功能是确定数据来源,而且数据来源应该都是数据表,表是一种行列的集合,如果FROM子句里出现的子查询,其返回的结果一定是多行多列数据。
4.1 范例:查询出每个部门的编号、名称、位置、部门人数、平均工资
4.1.1 实现方式一:直接利用多边关联查询,后根据临时表数据实现多字段分组
SELECT d.deptno, dname, d.loc, COUNT(e.empno), AVG(e.sal) FROM emp e, dept d WHERE e.deptno(+)=d.deptno GROUP BY d.deptno, d.dname, d.loc;
4.1.2 实现方式二:子查询完成
- 第一步:查询出部门编号、人数、平均工资
SELECT deptno, COUNT(empno), AVG(sal) FROM emp GROUP BY deptno;
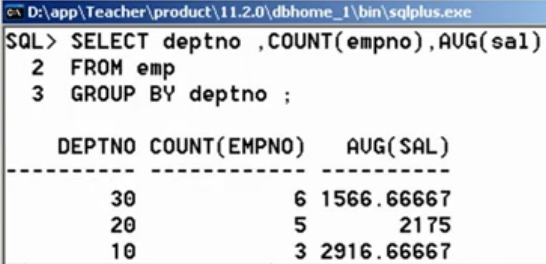
- 第二步:以上返回的数据是多行多列,当做一张数据表处理,只要在FROM后出现,需要部门名称和位置,还需要引入dept表,即:让dept表和以上的查询结果表一起做后续查询
SELECT d.deptno, d.dname, d.loc, temp.count, temp.avg
FROM dept d, (
SELECT deptno, COUNT(empno) count, AVG(sal)
FROM emp
GROUP BY deptno) temp
WHERE d.deptno=temp.deptno(+);
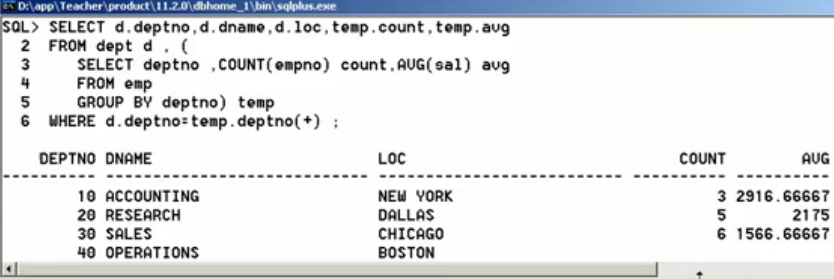
通过第二种实现,但相对于第一种,代码变复杂了,为了分析好处,假设数据扩大1000倍,即:emp表中有14000条数据,dept表中有4000条数据。
- 采用实现一的数据量,方式一采用多字段分组,需要多表查询,多表查询会产生笛卡尔积。
- 积的数量:emp的14000条 * dept的4000条 = 56,000,000条数据;
- 采用实现二的数据量,方式二采用子查询完成,需要两步完成
- 第一步(内嵌子查询):针对emp表查询,最多操作14000条记录,最多返回4000条
- 第二步,子查询和dept表关联
- 积的数量:dept表4000条 * 子查询返回的最多4000条数据 = 16000000条
- 总的数据量:16000000 + 14000 = 16,014,000条记录。
5. 子查询的目的
- 主要目的:子查询的出现主要是为了解决多表查询中的性能问题
- 次要目的:很多时候,在FROM子句中使用子查询,是因为外部查询里无法继续使用统计函数。
6. 子查询综合实例
范例:要求查询出高于公司平均工资的雇员姓名、职位、工资、部门名称、部门人数、部门平均工资、工资等级、此等级的雇员人数、领导姓名、领导职位
- 确定已知的数据表:
- Emp表:统计公司的平均工资;
- Emp表:雇员姓名、职位、工资;
- Emp表:自身关联,找到领导姓名、领导职位;
- Dept表:部门名称;
- Emp表:统计部门人数、部门平均工资;
- Salgrade表:工资等级;
- Emp表:统计一个工资等级的人数。
- 确定已知的关联字段:
- 雇员和领导:mgr = memp.empno;
- 雇员和部门:deptno = dept.deptno。
第一步:找到公司的平均工资
SELECT AVG(sal) FROM emp;
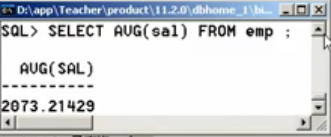
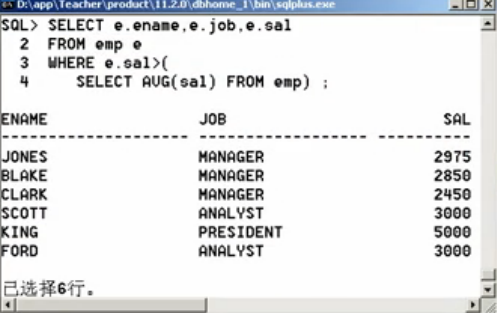
第二步:找到高于此平均工资的雇员姓名、职位、工资,直接将第一步的查询作为WHERE的限定条件
SELECT e.ename, e.job, e.sal
FROM emp e
WHERE e.sal>(
SELECT AVG(sal) FROM emp);
第三步:找到领导姓名和领导职位,直接使用emp表作为自身关联使用
SELECT
e.ename雇员姓名, e.job 雇员职位, e.sal 雇员工资,
m.ename 领导姓名, m.job 领导职位
FROM emp e, emp m
WHERE e.sal>(
SELECT AVG(sal) FROM emp);
AND e.mgr=m.empno(+);
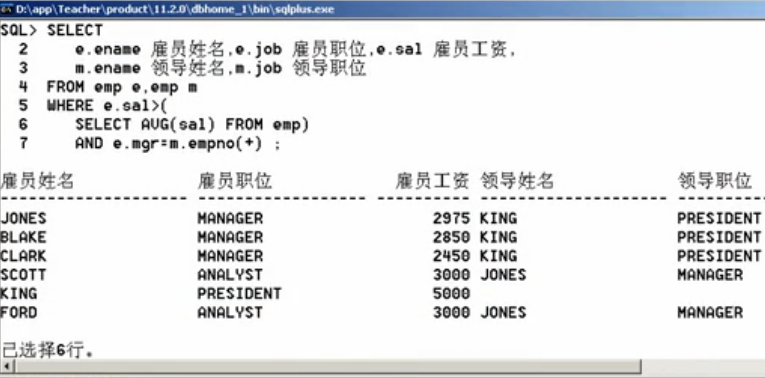
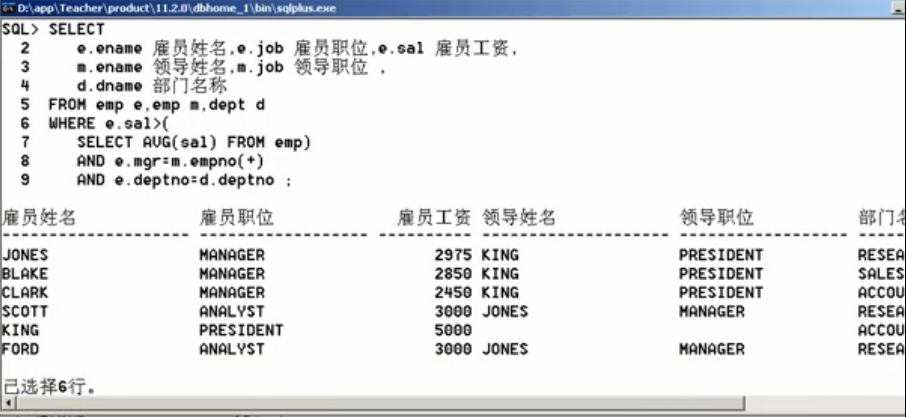
第四步:加入dept表,找到部门名称,
SELECT
e.ename雇员姓名, e.job 雇员职位, e.sal 雇员工资,
m.ename 领导姓名, m.job 领导职位,
d.dname 部门名称
FROM emp e, emp m, dept d
WHERE e.sal>(
SELECT AVG(sal) FROM emp);
AND e.mgr=m.empno(+)
AND e.dpetno = d.deptno;
第五步:统计部门人数,但是就当前给出的查询,现在不可能在SELECT子句里编写COUNT函数了(COUNT要么单独使用,要么结合GROUP BY使用,唯一可能出现在SELECT里的只有统计函数与分组字段)。所以,次数需要统计查询,但又无法使用统计函数,那就编写FROM子句中的子查询,然后再在FROM子句里查询部门人数:
SELECT deptno dnp, COUNT(empno) count FROM emp GROUP BY deptno;
将该查询结果作为上面FROM子句里的内容:
SELECT
e.ename雇员姓名, e.job 雇员职位, e.sal 雇员工资,
m.ename 领导姓名, m.job 领导职位,
d.dname 部门名称,
dtemp.count 部门人数
FROM emp e, emp m, dept d, (
SELECT deptno dno, COUNT(empno) count
FROM emp
GROUP BY deptno) dtemp
WHERE e.sal>(
SELECT AVG(sal) FROM emp);
AND e.mgr=m.empno(+)
AND e.dpetno = d.deptno
AND dtemp.dno=d.deptno;
第六步:找到工资等级,直接加入salgrade即可
SELECT
e.ename 雇员姓名, e.job 雇员职位, e.sal 雇员工资,
m.ename 领导姓名, m.job 领导职位,
d.dname 部门名称,
dtemp.count 部门人数,
s.grade 工资等级
FROM emp e, emp m, dept d, (
SELECT deptno dno, COUNT(empno) count
FROM emp
GROUP BY deptno) dtemp,
salgrade s
WHERE e.sal>(
SELECT AVG(sal) FROM emp);
AND e.mgr=m.empno(+)
AND e.dpetno = d.deptno
AND dtemp.dno=d.deptno
AND e.sal BETWEEN s.losal AND s.hisal;
第七步:找出工资等级的雇员人数,依然需要编写一个子查询进行统计
SELECT s1.grade sg, COUNT(e1.empno) count FROM emp e1, salgrade s1 WHERE e1.sal BETWEEN s1.losal AND s1.hisal GROUP BY s1.grade;

这个是工资等级对应的人数,我们现在将工资等级和人数表与刚刚的结果吧表穿插到一起。
SELECT
e.ename雇员姓名, e.job 雇员职位, e.sal 雇员工资,
m.ename 领导姓名, m.job 领导职位,
d.dname 部门名称,
dtemp.count 部门人数,
s.grade 工资等级,
stemp.count 等级人数
FROM emp e, emp m, dept d, (
SELECT deptno dno, COUNT(empno) count
FROM emp
GROUP BY deptno) dtemp,
salgrade s, (
SELECT s1.grade sg, COUNT(e1.empno) count
FROM emp e1, salgrade s1
WHERE e1.sal BETWEEN s1.losal AND s1.hisal
GROUP BY s1.grade) stemp
WHERE e.sal>(
SELECT AVG(sal) FROM emp);
AND e.mgr=m.empno(+)
AND e.dpetno = d.deptno
AND dtemp.dno=d.deptno
AND e.sal BETWEEN s.losal AND s.hisal
AND s.grade=stemp.sg;
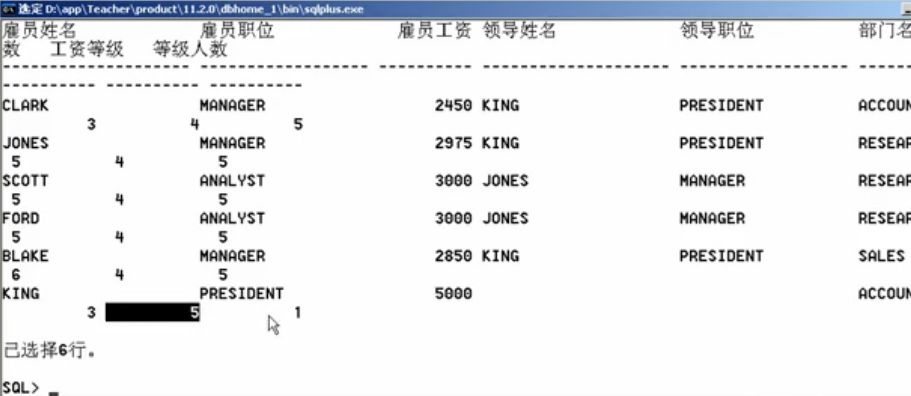
以上就是一个复杂查询,通过本程序可得到一个结论:复杂查询 = 限定查询 + 多表查询 + 统计查询。这部分的内容是最有可能出现在笔试中的题目,而且现在的表还是在你熟悉的情况下,如果是不熟悉的表,只能够需要根据表结构进行分析、掌握分析方法。
7. 总结
7.1 单行函数
| No. | 方法名称 | 类型 |
| 1 | 字符串 UPPER(字符串 | 数据列) | 将特定的字符串或者指定的列数据变为大写 |
| 2 | 字符串 LOWER(字符串 | 数据列) | 将特定的字符串或者指定的列数据变为小写 |
| 3 | 字符串 INITCAP(字符串 | 列) | 将特定字符串或者指定列的数据的首字母大写,其余字母小写 |
| 4 | 数字 LENGTH(字符串 | 列) | 计算出指定字符串或者数据列的数据长度 |
| 5 | 字符串 REPLACE(字符串 | 列,要替换的内容,新的内容) | 将指定字符串或者数据列中的数据按照指定的新内容 |
| 6 | 字符串 SUBSTR(字符串 | 数据列,截取开始索引) | 由指定位置截取到结尾 |
| 7 | 字符串 SUBSTR(字符串 | 数据列,截取开始索引,截取结束索引) | 指定截取的开始和结束位置 |
| 8 | 字符串 TRIM(字符串 | 列) | 去掉左右空格函数 |
| 9 | 数字 ROUND(数字 | 列 [,保留小数位]) | 四舍五入操作 |
| 10 | 数字 TRUNC(数字 | 列 [,保留小数位]) | 截取小数 |
| 11 | 数字 MOD(数字1 | 列1,数字2 | 列2) | 求模(余数) |
| 12 | 数字MONTHS_BETWEEN(日期1 | 列1,日期2 | 列2) | 计算两个日期之间所经历的月数 |
| 13 | ADD_MONTHS(日期 | 列,月数) | 在指定日期上增加若干月之后的日期 |
| 14 | 日期 NEXT_DAY(日期 | 列,一周时间数) | 求出指定的下一个一周时间数的日期 |
| 15 | 日期 LAST_DAY(日期 | 列) | 求出指定日期所在月的最后一天日期 |
| 16 | 字符串 TO_CHAR(数字 | 日期 | 列,转换格式) | 转字符串数据 |
| 17 | 日期 TO_DATE(字符串,转换格式) | 转日期数据 |
| 18 | 数字 TO_NUMER(字符串,转换格式) | 转数字数据 |
| 19 | 数字NVL(列 | 数据,默认值) | 处理NULL数据 |
| 20 | 数据DECODE(字段 | 数据,判断数据1,显示数据1,判断数据2,显示数据2,…[默认显示]) | 多数据判断、 |
7.2 SQL查询语法的结构
| SELECT [DISTINCT] * | 列名称 [别名], 列名称 [别名], … | 统计函数 FROM 数据表 [别名], 数据表 [别名], … [WHERE 条件(s)] [GROUP BY 分组字段, 分组字段,…] [HAVING 分组后过滤] [ORDER BY 字段 [ASC | DESC], 字段 [ASC | DESC], …] | 5.确定数据列 |
| 1.数据源 | |
| 2.过滤数据行 | |
| 3.执行分组 | |
| 4.针对分组过滤 | |
| 6.数据排序 |
查询就以上的几个子句,使用熟练。
8. 参考
- 『李兴华java培训01』Oracle数据库 - 网易云课堂 http://study.163.com/course/courseLearn.htm?courseId=932016#/learn/video?lessonId=1115372&courseId=932016