Peripateticism
Yuens' blog

分组函数与分组统计查询的SQL语法
内容参考《李兴华Oracle数据库》的SQL分组函数与分组统计查询部分(链接见文末参考),本节主要包括:[toc]
1.组函数
COUNT函数主要功能是表中数据量统计,属于一种统计函数。常见的五个统计函数:COUNT()、SUN()、AVG()、MAX()、MIN()。
1.2 范例:统计所有雇员的人数、支付的总工资、平均工资、最高工资、最低工资
SELECT COUNT(*), SUM(sal), AVG(sal), MAX(sal) MIN(sal) FROM emp;
1.2 范例:统计公司支付的总年薪与平均年薪
SELECT SUM((sal+NVL(comm, 0)) * 12), AVG((sal+NVL(comm, 0) * 12) FROM emp;
1.3 范例:求出公司最早雇佣雇员的日期和最晚雇佣雇员的日期
SELECT MAX(hiredate), MIN(hiredate) FROM emp;
1.4 面试题:请解释“COUNT(*)”、“COUNT(字段)”、“COUNT(DISTINCT 字段)”
SELECT COUNT(*), COUNT(empno), COUNT(comm), COUNT(DISTINCT job) FROM emp;
- COUNT(*):会实际地统计出表中的数据量;
- COUNT(字段):
- 如果统计的字段不包含有NULL,那么与COUNT(*)结果相同;
- 如果统计的字段包含有NULL,NULL不参与统计;
- COUNT(DISTINCT 字段):消除重复数据后统计。
2. 分组统计(难点)
在讲解具体的分组统计操作前必须要先解决一个问题,什么情况下有可能分组?
- 例如:全班,男生一组,女生一组,互相拔河;
- 例如:全班,戴眼镜一组,不戴眼镜一组,互相比裸眼视力;
- 例如:25岁前一组,之后一组,比年轻。
实际上所谓的分组,指的某些群体具备共同的特征。现在回到emp表中,可以发现job和deptno因为存在重复数据,所以可分组,
但一定要记住,一条记录也可分组。只不过这类的做法没有意义。如果要实现统计查询,那么可以采用如下的语法完成,如果想实现统计查询,那么可采用如下语法完成:
| SELECT [DISTINCT] * | 列名称 [别名], 列名称 [别名], … | 统计函数 FROM 数据表 [别名], 数据表 [别名], … [WHERE 条件(s)] [GROUP BY 分组字段, 分组字段, …] [ORDER BY 字段 [ASC | DESC], 字段 [ASC | DESC], …] | 步骤四:确定查询列 |
| 步骤一:确定数据源 | |
| 步骤二:过滤数据行 | |
| 步骤三:执行分组操作 | |
| 步骤五:数据排序 |
2.1 范例:按职位分组,统计出每个职位的平均工资、最高和最低工资、人数
SELECT job, AVG(sal), MAX(sal), MIN(sal), COUNT(*) FROM emp GROUP BY job;
2.2 范例:按照部门编号分组,统计出每个部门的人数、平均工资、平均服务年限
SELECT COUNT(*), AVG(sal), AVG(MONTHS_BETWEEN(SYSDATE, hiredate)/12) FROM emp GROUP BY deptno;
提示:关于统计查询的几个重要说明
以上的代码只是根据基础语法实现了统计操作,但在整个操作中仍有三个限制:
- 限制一:统计函数在单独使用的时候(没有GROUP BY子句)只能够出现统计函数,不能够出现其它字段。
| 正确代码 | 错误代码 |
| SELECT COUNT(empno) FROM emp; | SELECT COUNT(empno), ename FROM emp; |
- 限制二:使用统计查询时(存在GROUP BY子句),SELECT子句之中只能出现统计函数的分组字段,其它字段都不允许出现。
| 正确代码 | 错误代码 |
| SELECT deptno, COUNT(empno) FROM emp GROUP BY detpno; | SELECT deptno, COUNT(empno),ename FROM emp GROUP BY detpno; |
- 限制三:统计函数在分组之中可以嵌套使用,但是嵌套之后的统计查询之中,不能使用任何字段,包括统计分组字段。
| 正确代码 | 错误代码 |
| SELECT MAX(COUNT(empno)) FROM emp GROUP BY detpno; | SELECT deptno, MAX(COUNT(empno)) FROM emp GROUP BY detpno; |
在整个分组操作之中,以上的三个限制可以是最难理解的。一定要搞清楚。
以上的操作都是针对单张表一个字段的分组,那么通过先前给出的语法格式可发现,分组可设置多个字段,那么这就要求这多个字段必须同时重复。
2.3 范例(开始):查询出每个部门的名称、部门人数、平均工资
- 确定所需数据表:
- dept表:找到部门名称;
- emp表:统计部门人数、平均工资。
- 确定已知的关联字段:
- 雇员和部门关联:deptno=dept.deptno
SELECT d.dname, e.empno, e.sal FROM emp e, dept d WHERE e.deptno=d.deptno;
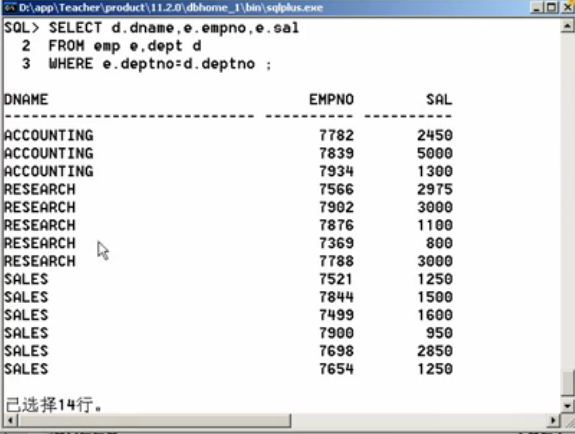
第二步:在上面查询结果中发现部门名称是重复的,但此时并不是一张实际表操作,而是针对一张临时查询结果进行分组操作,由于GROUP BY在WHERE之后执行,所以可直接分组。
SELECT d.dname, COUNT(e.empno), AVG(e.sal) FROM emp e, dept d WHERE e.deptno=d.dpetno GROUP BY d.dname;
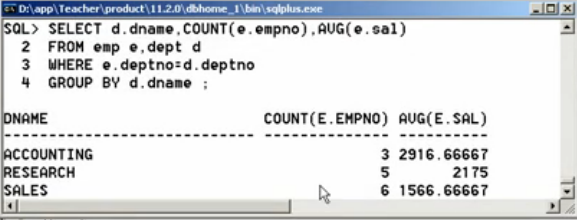
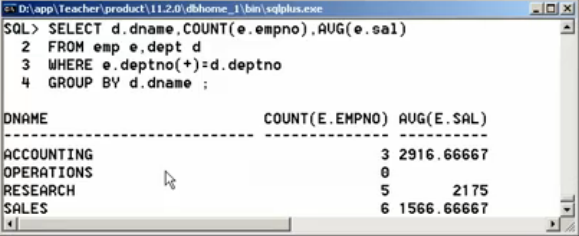
第三步:现在引入dept表,其中表示有四个部门,而此时只有三个部门,那么此时就需要外连接进行40部门的数据显示。
SELECT d.dname, COUNT(e.empno), AVG(e.sal) FROM emp e, dept d WHERE e.deptno(+)=d.dpetno GROUP BY d.dname;
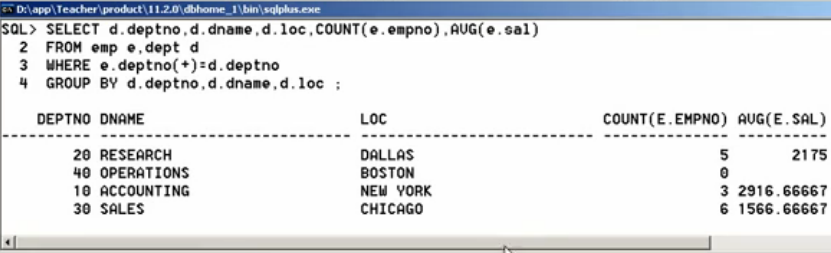
2.4 范例(完结):查询出每个部门的编号、名称、位置、部门人数、平均工资
- 确定所需数据表:
- dept表:找到部门编号、名称、位置;
- emp表:统计部门人数、平均工资。
- 确定已知的关联字段:
- 雇员和部门关联:deptno=dept.deptno
第一步:首先不去考虑分组,先实现多表查询,查询部门编号、名称、位置、雇员编号
SELECT d.deptno, d.dname, e.loc, d.empno, e.ename FROM emp e, dept d WHERE e.deptno=d.dpetno;
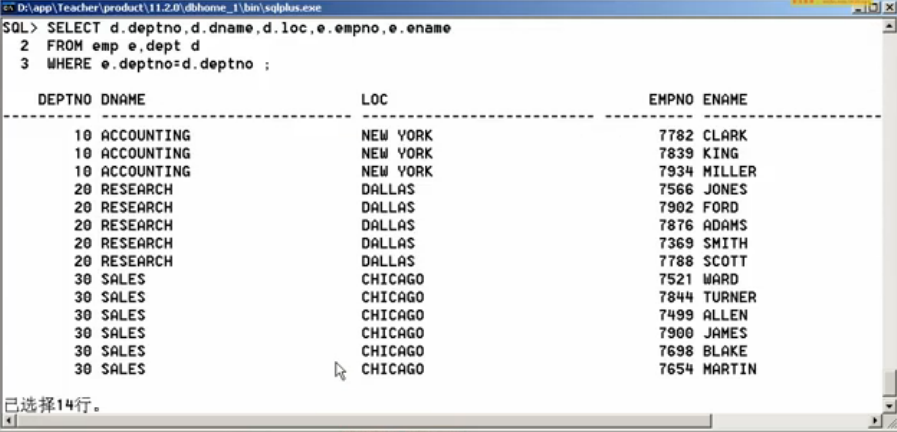
现在发现部门的数据三个字段都是在整体重复着,那么针对三个字段实现分组:
SELECT d.deptno, d.dname, d.loc, COUNT(e.empno), AVG(e.ename) FROM emp e, dept d WHERE e.deptno(+)=d.dpetno GROUP BY d.deptno, d.dname, d.loc;
2.5 范例:按照职位分组,统计每个职位的平均工资,要求显示的是平均工资高于2000的职位信息
现在唯一可以想到的条件过滤只有WHERE子句一个。于是现在编写出如下代码:
SELECT FROM emp WHERE AVG(sal)>2000 GROUP BY job;
意思是WHERE子句中不能够使用分组(即统计)函数,通过先前的分析也该知道,WHERE是在GROUP BY之前使用的,而此时的条件明显是在GROUP BY后的过滤,这时只能使用HAVING子句完成,语法如下:
| SELECT [DISTINCT] * | 列名称 [别名], 列名称 [别名], … | 统计函数 FROM 数据表 [别名], 数据表 [别名], … [WHERE 条件(s)] [GROUP BY 分组字段, 分组字段,…] [HAVING 分组后过滤] [ORDER BY 字段 [ASC | DESC], 字段 [ASC | DESC], …] | 5.确定数据列 |
| 1.数据源 | |
| 2.过滤数据行 | |
| 3.执行分组 | |
| 4.针对分组过滤 | |
| 6.数据排序 |
2.6 范例:使用HAVING修改程序
SELECT job, AVG(sal) FROM emp GROUP BY job HAVING AVG(sal) > 2000;
解释:关于WHERE和HAVING的区别
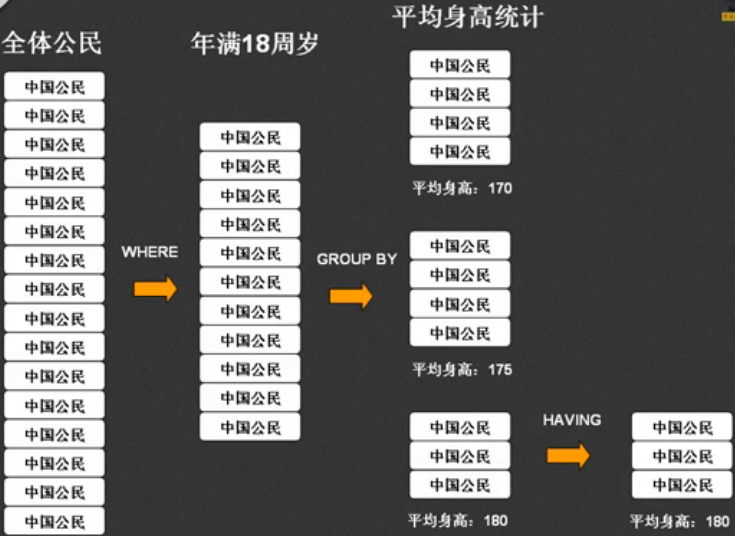
- WHERE子句:是在分组前使用,而且不能够使用统计函数进行验证,经过WHERE筛选后的数据才可分组;
- HAVING子句:必须结合GROUP BY子句一起出现,是在分组后过滤,可以使用统计函数。
2.7 思考题一:统计公司每个工资等级的人数、平均工资
- 确定要使用的数据表:
- salgrade表:工资等级;
- emp表:统计人数、平均工资;
- 确定已知的关联字段:
- 工资与工资等级:sal BETWEEN salgrade.losal AND salgrade.hisal。
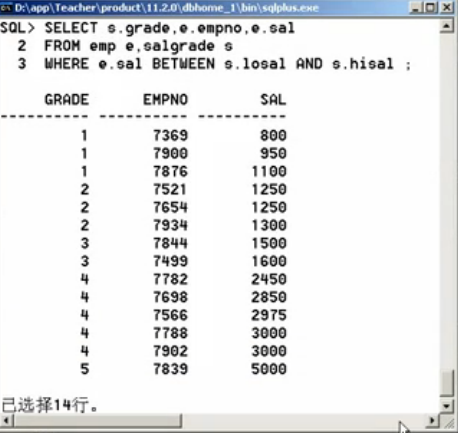
第一步:查询出工资等级,以及每个雇员的编号、工资,直接实现了多表查询。
SELECT FROM emp e, salgrade s WHERE e.sal BETWEEN s.losal AND hisal;
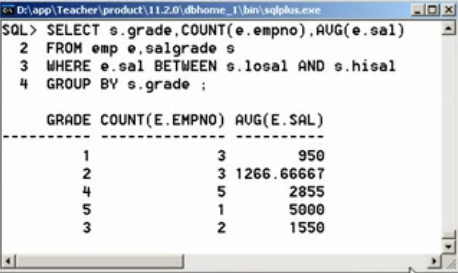
第二步:针对临时数据表中的数据进行分组
SELECT s.grade, COUNT(e.empno), AVG(e.sal) FROM emp e, salgrade s WHERE e.sal BETWEEN s.losal AND hisal; GROUP BY s.grade;
2.8 思考题二:统计出领取佣金和不领取佣金的人数、平均工资
现在很容易联想到,针对comm字段分组,写出如下语句:
SELECT comm, COUNT(empno), AVG(sal) FROM emp GROUP BY comm;
所以此时这个查询结果发现并不理想,不如换个思路。
第一步:统计出所有领取佣金的人数
SELECT ‘领取佣金’, COUNT(empno), AVG(sal) FROM emp WHERE comm IS NOT NULL;
第二步:统计出所有不领取佣金的人数
SELECT ‘不领取佣金’, COUNT(empno), AVG(sal) FROM emp WHERE comm IS NULL;
第三步:以上两个查询返回的结构完全相同,合并为一个结果
SELECT ‘领取佣金’, COUNT(empno), AVG(sal)
FROM emp
WHERE comm IS NOT NULL
UNION
SELECT ‘不领取佣金’, COUNT(empno), AVG(sal)
FROM emp
WHERE comm IS NULL;
很多时候都可以直接进行分组,但是在进行分组的时候,必须保证数据列上有重复,但如果是针对一些条件,只能利用以上的方式完成。
3. 参考
- 『李兴华java培训01』Oracle数据库 - 网易云课堂 http://study.163.com/course/courseLearn.htm?courseId=932016#/learn/video?lessonId=1116382&courseId=932016